Analyse de la variance de base (1 et 2 facteurs) – ch. 15 à 21 Analyse de covariance – ch. 22 Analyse de la variance multifactorielle – ch. 23 à 25 Analyse de la variance avancée – ch. 26 à 28 Plans d’expériences 2k-p - ch. 29 - hors programme Response Surface Methodology - ch. 30 - hors programme
AutresBelsley, D.A., E. Kuh, R.E. Welsch (1980). Regression Diagnostics. John Wiley.Cook, R. D., S. Weisberg (1982). Residuals and Influence in Regression. Chapman & Hall.Daniels, C., F. Wood (1980). Fitting Equations to Data, John Wiley. Draper, N. R., H. Smith (1981). Applied Regression Analysis. 2nd ed. John Wiley.Jobson, J. D. (1991). Applied Multivariate Data Analysis, vol. 1, Springer.Kuehl, R.O. (2000). Designed Experiments, Statistical Principles of Research and Analysis. Duxbury Press. Lunneborg, C. E. (1984). Modeling Experimental and Observationnal Data. Duxbury Press.Miliken, G.A., D. E. Johnson. Analysis of Messy Data, Volume 1: Designed Experiments, 2nd Edition.
Chapman & Hall/CRCPress, New York. 2009Analysis of Messy Data, Vol. 2: Nonreplicated Experiments. Chapman & Hall/CRC, 1989.Analysis of Messy Data, Vol. 3: Analysis of Covariance., Chapman & Hall/CRC, 2001.
Montgomery, D. C., E.A. Peck, G. G. Vining (2006). Introduction to Linear Regression Analysis, 4th ed. Wiley. Tenenhaus, M. (1998). La régression PLS, Éditions Technip.
3chapitre 1
MTH8302 - Analyse de régression et analyse de variance
Chapitre 1-Introduction Modélisation statistique Modèles statistiques Étapes d’une analyse statistique Classification des modèles
Chapitre 2-Simple Modèle LINÉAIRE SIMPLE Transformations et modèles linéarisables Modèles non linéaires Modèle Logistique
Chapitre 3-Multiple – partie 1 Modèle de régression MULTIPLE Régression avec STATISTICA Exemple d’utilisation et interprétation Inférence pour modèle réduit Variables standardisées Méthodes de sélection de variables
(model building) Critères de sélection de modèles
Chapitre 4-Multiple – partie 2 Résidus, influence, validation croisée Multicolinéarité Régression biaisée ridge Régression sur composantes principales Variables explicatives catégoriques
Chapitre 5-Multiple – partie 3 Régression : variables explicatives catégoriques Régression : modèles non linéaire Régression logistique: variable réponse Y binaire Régression : variable de réponse Y Poisson Modèles lin. généralisés: variable Y non normale
Data Mining CART : Classification And Regression Trees Réseau de neurones MARS : Multivariate Adaptive Regression Splines
Modèles d’analyse de la varianceChapitre 1 – chapitre 2 – chapitre 3 chapitre 4 – chapitre 5
4
Concepts de la modélisation et analyse statistique
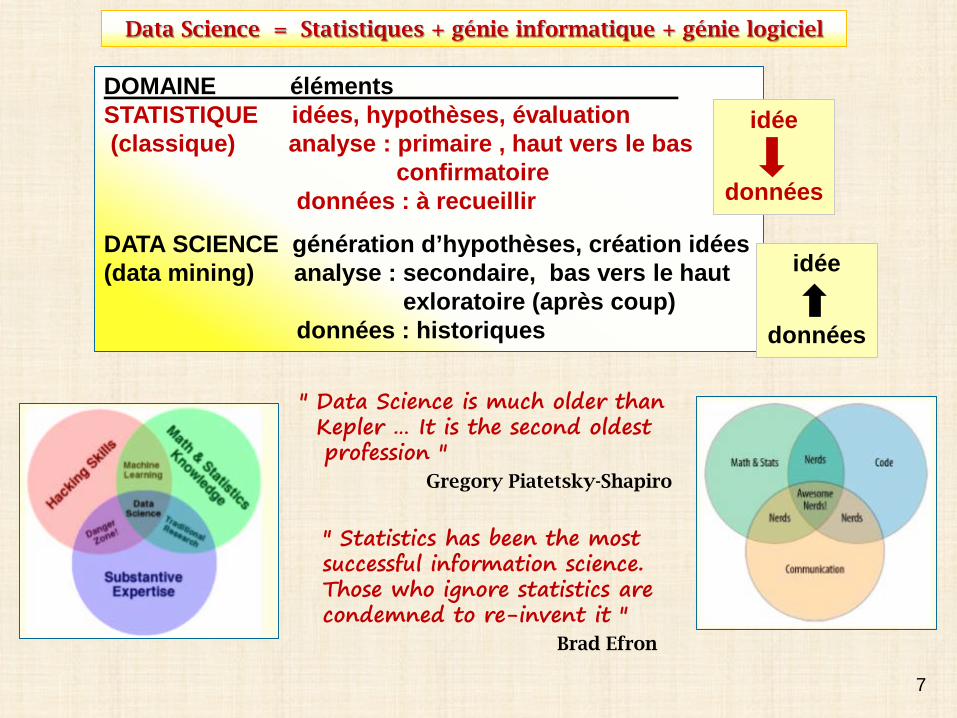
autre distinctionCLASSIQUE (traditionnelle) : base inférentielleMÉGADONNÉES (nouvelle) : base algorithmique
Type d’études statistiques
10
Type d’étude Statistique
* L’homogénéité des données est fondamentale lors de leur l’analyse.Cette question est clarifiée dans l’article suivant :Wheeler, Donald J. (2009) The four Questions of Data Analysis
MTH8302 - Analyse de régression et analyse de variance
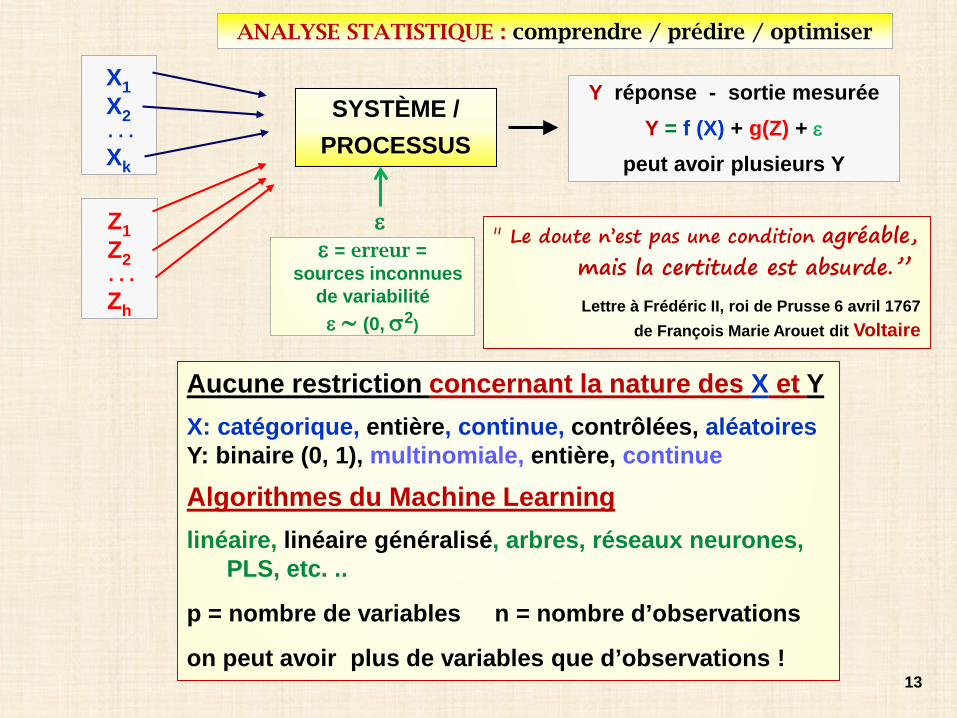
VARIABLESNature: continue - catégoriqueRôle: explicatives (X = input) - à expliquer (Y = output = réponse)Liste des X complète? k = nombre OK?Mesure de Y - processus de mesure / erreur? justesse?
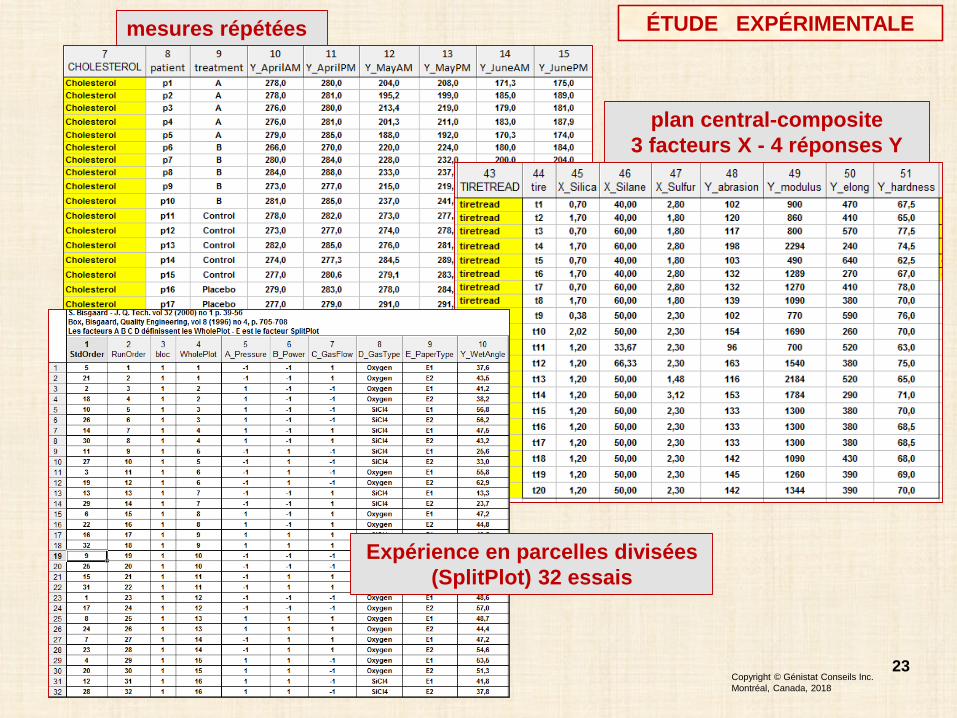
STRUCTURE et le PLAN de collecte des donnéesexpérience planifiée - quel plan statistique?
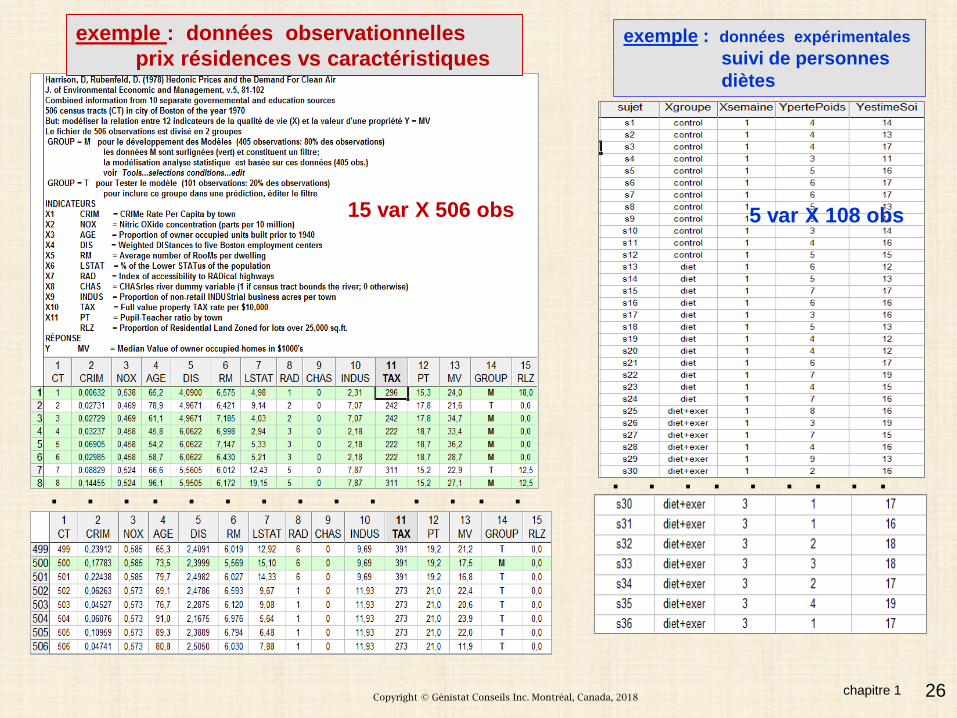
- combien de données? n?données observées sans plan expérimental – qualité?
Terme d’erreur expérimentale - distribution normale? importance?importance obsessive sur la normalité
Forme de f - connue – linéaire / non linéaire (cas plutôt rare)- inconnue - quelle approximation? – polynomiale?- techniques de sélection des variables pour modéliser- qualité du modèle ajusté? critères?
Ajustement du modèle - analyse de sensibilité des X
Évaluation de qualité du modèle - analyse des résidus
- validation croisée
ÉTAPES ÉTUDE STATISTIQUE
1. Identification processus / problème / variables2. Observation plan collecte des données3. Spécification modèle pour analyse4. Estimation paramètres du modèle5. Décomposition variabilité (ANOVA), test F6. Validation tests, ratio-F, analyse résidus7. Exploitation optimisation / résolution problème
décision / action
ÉTAPES : ANALYSE
STATISTIQUE
1. Spécification d’un modèle statistique2. Estimation des paramètres du modèle3. Décomposition de la variabilité : ANOVA4. Tests d’hypothèses sur les paramètres 5. Analyse diagnostique des résidus
- vérification des hypothèses de base- identification d’observations influentes- transformation réponse Y ?
6. Si nécessaire : itération des étapes 1 à 57. Optimisation de la réponse (s’il y a lieu)8. Graphiques de la réponse 16
Y = f (X1, X2 , … , Xk ; β0 , β1 , β2 ,… )+ g (Z1, Z2, .., Zh ; σ1
2 , σ22 , …) + ε (0, σ2)
18
Variables et modèles
Classification des modèles statistiques
chapitre 1
MTH8302
Modèle général Y = φ(X1, X2,…, Xk; β0, β1, β2 ,…, βp) + ε ε ~ N(0,σ2) (1)
Modèle LINÉAIRE dans les β si
Modèle sans variable explicative: Y = β0 + ε
Modèle de régression par l’origine: Y = β1X + ε
Modèle de régression linéaire simple: Y = β0 + β1X + ε
Modèle de régression linéaire multiple: k ≥ 2 ou plus variables explicativesModèles intrinsèquement linéaires: linéaires après transformations sur X et ou Y
Modèles intrinsèquement non linéaires: équations (2) et (3) non satisfaites et aucune transformation sur X ou Y ne permet de se ramener à ce casexemple: Y = β0 + β1exp(β2X) + ε