27
Discriminative Training in Speech Processing Filipp Korkmazsky LORIA
| Date post: | 14-Dec-2015 |
| Category: |
Documents |
| Upload: | maximo-burnham |
| View: | 216 times |
| Download: | 0 times |

Discriminative Training in Speech Processing
Filipp Korkmazsky
LORIA

Content
• Bayes Decision Theory and DiscriminativeTraining
• Minimum Classification Error(MCE) Training• Generalized Probabilistic Descent(GPD) algorithm• MCE Training versus Maximum Mutual Information(MMI) Training• Discriminative Training for Speech Recognition• Discriminative Training for Speaker Verification

• Discriminative Training for Feature Extraction
• Discriminative Training of Language Models
• Discriminative Training for Speech/Music
Classification
• Conclusions

• Main assumption of Bayes decision theory:
a joint probability functions are known, where X is an observation and
are class labels.
Decision cost function:
(1)
),( iCXP
Bayes Decision Theory and Discriminative Training
),,1( MiCi
)()(1
XCPeXCR j
M
jjii
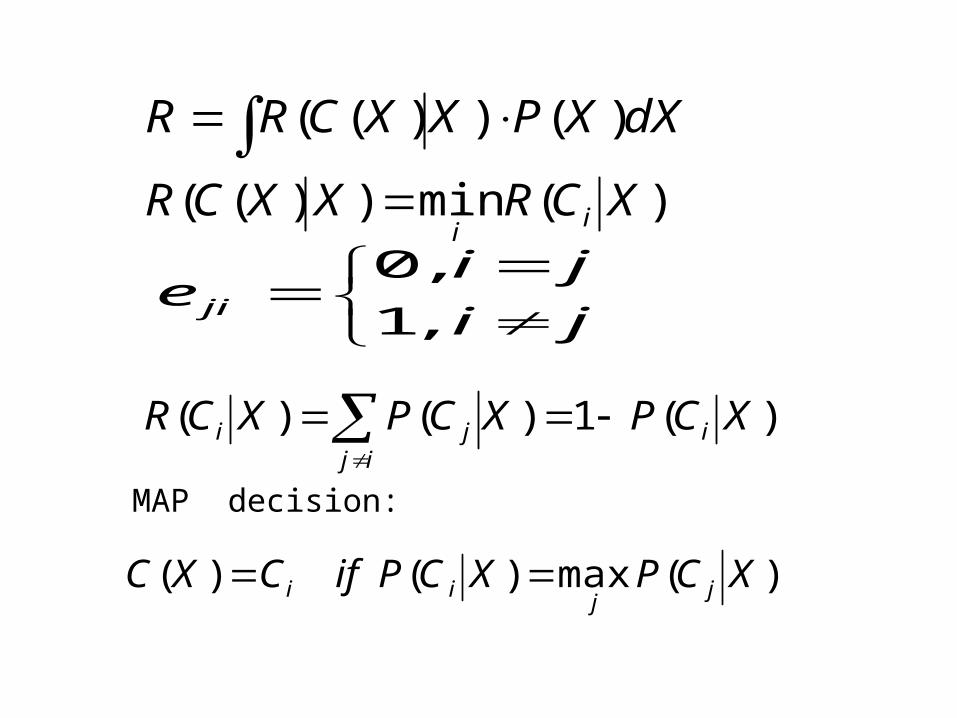
(2)
(3) (4)
(5) MAP decision:
(6)
dXXPXXCRR )())(( )(min))(( XCRXXCR i
i
j
j
i
ie ji
,1
,0
)(1)()( XCPXCPXCR iij
ji
)(max)()( XCPXCPifCXC jj
ii

Why MAP decision is not optimal for real speech data?
• Probability distribution of speech data is
usually uknown and a postulated HMM
approximation for this distribution doesn’t
provide a MAP optimal solution.• Even if HMM was correct distribution for speech,
the lack of training data often doesn’t allow to accurately model probability distribution of competing speech classes near their boundaries.

Class I real distribution Class II real distribution
Class I postulated distribution Class II postulated distribution

Discriminative Functions
MiXgi ,1),,( Discriminative functions:
),(maxarg Xgj ii
),(maxarg),(),(,1,
XgXgXd jMjij
ii
)(minarg
)()),(()),(()(
)(1),(),(1
L
XXPXdlXdlEL
CXXdXd
opt
XX
M
iii
)(L - classification error
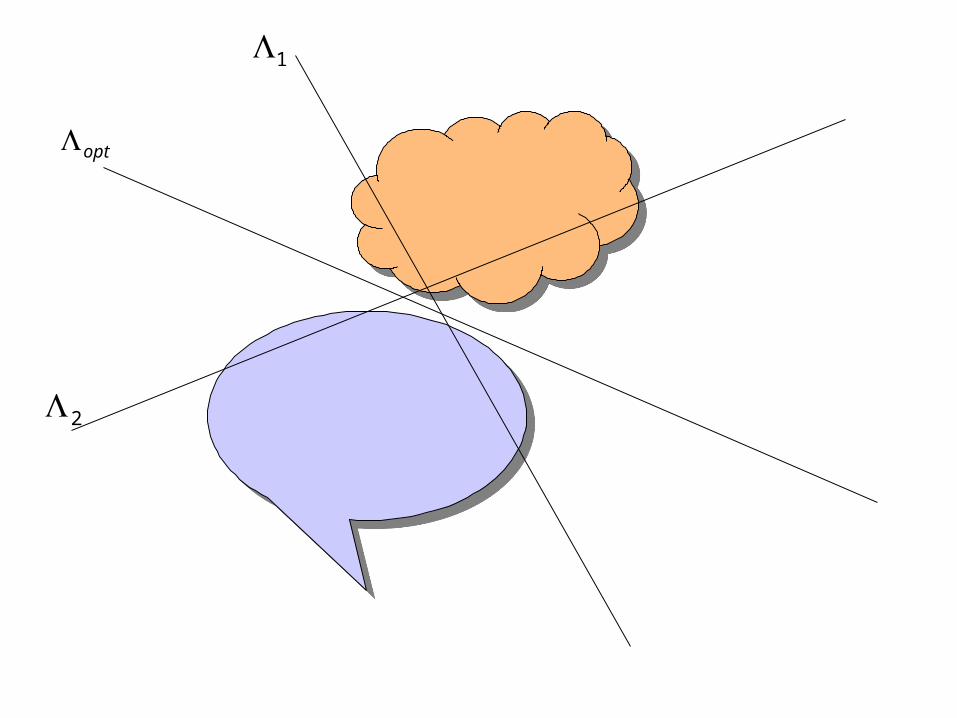
1
2
opt

Minimum Classification Error(MCE) Training
),(max),(),(,
),(exp1
1ln
1),(),(
1,
XgXgXdthenIf
XgM
XgXd
jij
ii
M
jijjii
0,))),((exp(1
1)),((
XdXdl
ii
)),(( Xdl i - a classification error for X

1
0
0.5
),( Xdi
)),(( Xdl i

Generalized Probabilistic Descent(GPD) Algorithm
t
tttttt
U
XlUt
0,),(1
positive definite matrix
t a set of HMMs at the step t of GPD algorithm
tX a speech sample(sentence, word, phone,frame) at the step t of GPD algorithm
Example: Gaussian mean correction by GPD algorithm
)()( tijkl a mean for the HMM i, state j, Gaussian mixture k,
dimension l at the step t of GPD algorithm

tijkl
tijkl
ijkl
Xltt
)(
)()( ),()()1(
)()(
),(
),(
),(),(ijkl
ijkl
Xd
Xd
XlXl
)),(1(),(),(
),(
XlXlXd
Xl
)(1
)(
),(
),(
),(),(ijkl
mM
m mijkl
Xg
Xg
XdXd

MCE Training versus Maximum Mutual Information Training
M
jjj
kk
CPCXP
CXPXI
1
)(),(
),(ln),(
M
kjjjj
kk
M
kjjjj
k
M
kjjjj
kk
CXPCP
CXPCXP
CPCXP
CXP
CPCXP
CPXI
,1
,1
,1
),(lnexp)(ln
),(ln),(
)(),(
ln
),(
)(),(
)(ln),(

M
kjjjjkk
jj
XgCPXgXd
CXPXg
,1
),(exp)(ln),(),(
),(ln),(
min),(max),(
),(),(
XdthenXIIf
XdXI
kk
kk
Maximization of mutual information corresponds to minimization of special type of classification error. Unlike general procedure of MCE maximization of mutual information doesn’t provide higher correction values to the parameters at the class boundaries. Minimization of classification error provides a better class separation at the class boundaries due to a form of the sigmoid function ),( Xl

Discriminative Training for Speech Recognition
1. Discriminative training is based on comparison the likelihood scores estimated for single speech units(phones, words). Examples:• E-set vocabulary recognition(W.Chou, 1992) Speaker independent recognition(100 speakers) ML training – 76% phone recognition accuracy MCE/GPD training – 88% phone recognition accuracy.• Broadcast news phone string recognition(Korkmazsky, 2003) ML training – 61.93% phone recognition accuracy MCE/GPD training – 65.11% phone recognition accuracy

N
nnWXg
NWXgXd
10 ),,(exp
1log
1),,(),(
0W a true word string, nW one of the N alternative word strings
nWW 0Examples:• Connected digit strings of uknown length recognition(Wu Chou,1993) ML training - 1.4% string error rate MCE/GPD training – 0.95% string error rate• Wireless noisy data digit strings recognition(Korkmazsky, 1997) ML training – 2.6% word error rate MCE/GPD training –1.4% word error rate Generalized HMM MCE/GPD training – 1.0% word error rate
2. Discriminative training is based on comparison the likelihood scores estimated for the strings of speech units(sentences)

Discriminative Training for Speaker Verification
)(log),(),(log),(
,
iitt
it
XPXgXPXg
a true talker and impostor HMMs
),(),(),( it XgXgXgthen X represents a true talker,0),( XgIf
then X represents an impostor,0),( XgIf
a verification threshold

),((exp1
1),(
)),((exp1
1),(
ii
tt
XdXl
XdXl
min),(),( it XlXlE E[A]-an expectation for A
Example: a speaker verification for database consisiting of 43speakers, each having 5 training sentences(Korkmazsky,1996)
ML training – 4.40% equal error rateMCE/GPD training – 2.50% equal error rate
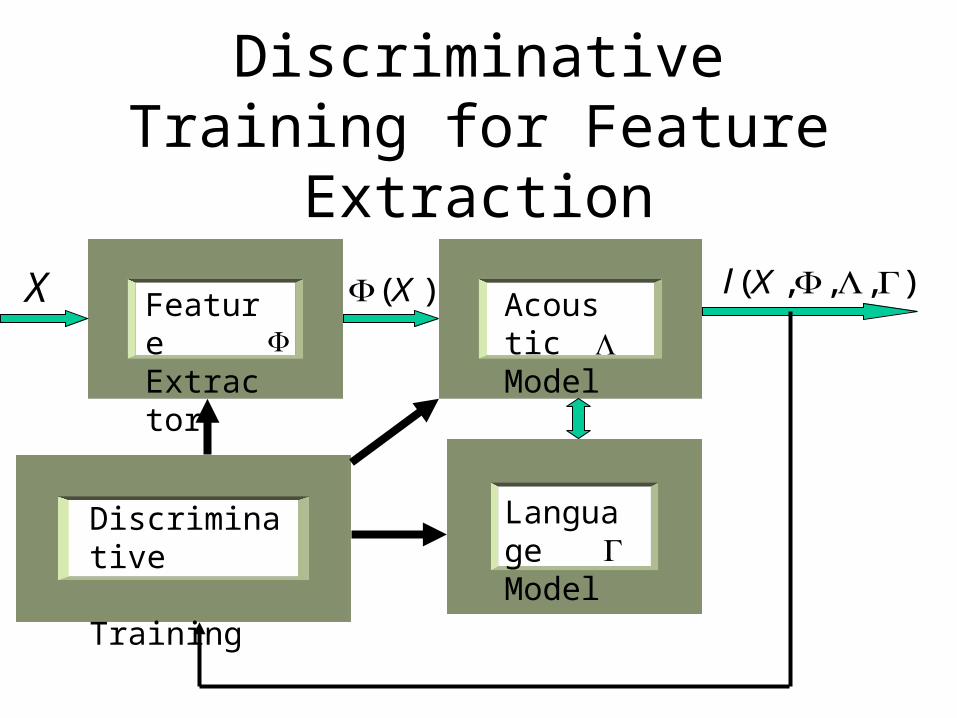
Discriminative Training for Feature Extraction
AcousticModel
FeatureExtractor
LanguageModel
Discriminative Training
X )(X ),,,( Xl

),,,(minarg
Xlopt
Examples: • Discriminative filter bank design(Biem, Katagiri, 1996):Central filter bank frequencies were adjusted by MCE/GPD training.First, 128 FFT spectral coefficients were converted to 16 Mel spectrum coefficients by using some convential frequency scale.The models for 5 japanese vowels were represented by the frequency templates. Recognition accuracy in this experiment was 80.91%. After MCE/GPD adjustment of the central band frequencies accuracy increased to 82.45%.• Discriminative training of the lifter coefficients(Biem, Juang,1997): Lifter coefficients weight quefrency values after cosine transform. Lifter weights were trained by adjusting neural network coefficients using MCE criterion. Error rate for 5 japanese vowels was reduced from 14.5% to 11.3%.

Discriminative Training of Language Models
(Zhen Chen, Kai-Fu Lee(1999), Jeff Kuo, Hui Jiang(2002))
)(
)()(maxarg)(maxarg
XP
WPWXPXWPW
WWopt
)(log),(log),,,( WPWXPWXg
),,,(maxarg
),,,(maxarg
11 ,,
1
WXW
WXgW
rWWWr
W
0W correct word sequence

),,,,,(),,,(),,( 10 NWWXGWXgXd
N
rrN WXg
NWWXG
11 ),,,(exp
1log
1),,,,,(
N
jj
rr
r
N
rr
WXg
WXgC
wwWICwwWIwwP
Xd
1
10
),,,(exp
),,,(exp
),(),()(
),,(
Discriminative correction of the bigram probabilities for all word pairs :
)( wwPww
),( wwWI r a number of times a word pair ww appears
in the word sequence rW
))(())(()()( wclasswPwwclassPwwPwwP
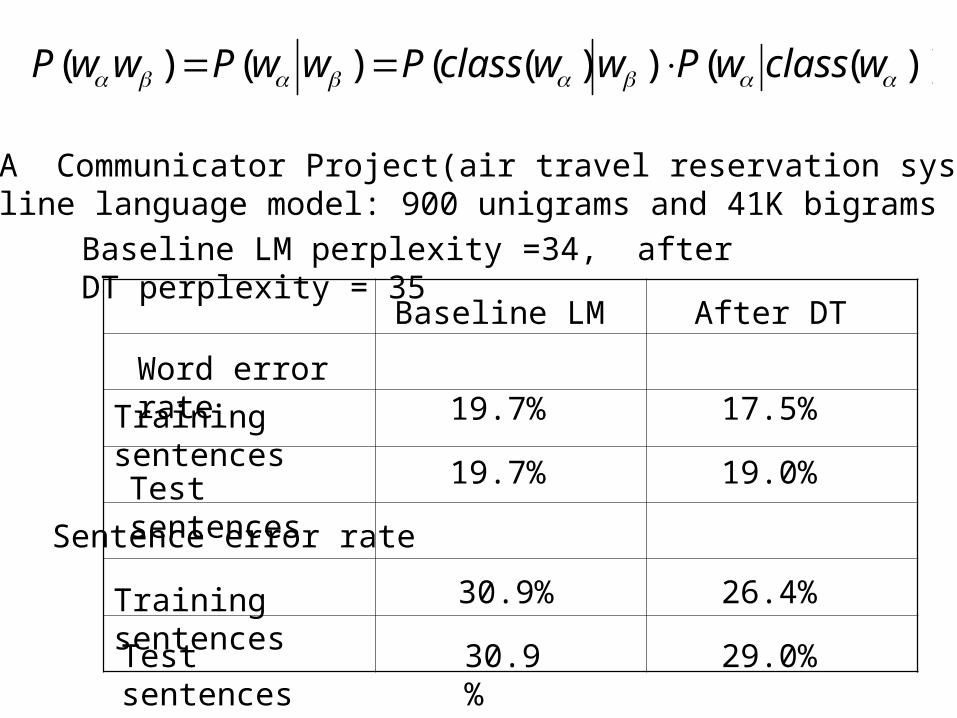
DARPA Communicator Project(air travel reservation system)Baseline language model: 900 unigrams and 41K bigrams
Word error rate
Training sentences
Training sentences
Test sentences
Test sentences
Sentence error rate
Baseline LM After DT
19.7%
19.7%
30.9%
30.9%
17.5%
19.0%
26.4%
29.0%
Baseline LM perplexity =34, after DT perplexity = 35

Discriminative Training for Speech/Music Classification
(Korkmazsky, 2003)Speech class: speech, speech&music in the background speech&song in the backgroundNonspeech class: music, song, noise(aspiration, cough, laugh)
654321 ,,,,,;6,,1)),,(( iXdl i
)3()2()1(
)3()2()1(
,,,
),,,(),(),(
iiii
iiiii
XXXX
XGXgXd
3
1
)3()2()1( ),(exp3
1ln
1),,,(
r
riiii XgXG

),(1
),(1
F
ffXlF
XL
),(XL block classification error
),( fXl frame f classification error
a total number frames in the blockF
a set of 6 GMMs
Frame labeling accuracy for ML trained GMMs – 90.5%Frame labeling accuracy for MCE trained GMMs – 92.7%

Conclusions
• Maximum likelihood training often does not provide optimal speech classification because real distribution of speech data is unknown.
• Discriminative training usually improves speech classification over ML training.
• Discriminative training may provide comparable to ML training recognition performance by using a
a smaller number of model parameters.• Many new methods of classification(like SVM or
boosting) are discriminative ones.

















