Page 1
Page 1 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop Crash Course
Summer 2015Version 1.0
Hadoop Interest Group
Jules Damji [email protected]
@2twitme
Rafael Coss [email protected]
@racoss
Page 2
Page 2 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop Crash Course
Why Hadoop?
Hadoop Ecosystem & Distribution
Store Data (HDFS)
Process Data in Hadoop 1 (MapReduce)
Process Data in Hadoop 2 (Yarn + MapReduce/Tez)
Data Access
Lab
Page 3
Page 3 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What disrupted the data center?
?
Data?
Page 4
Page 5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
New Data Paradigm Opens Up New Opportunity
2.8 zettabytesin 2012
44 zettabytesin 2020
N E W
1 zettabyte (ZB) = 1 million petabytes (PB); Sources: IDC, IDG Enterprise, and AMR Research
Clickstream
ERP, CRM, SCM
Web & social
Geolocation
Internet of Things
Server logs
Files, emails
Transform every industry via full fidelity of data and analytics
Opportunity
T R A D I T I O N A L
LAGGARDS
LEADERS
Ability to Consume Data
Enterprise Blind Spot
Page 5
Page 6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop YARN-based Architecture Unlocks Opportunity
Consolidates all data sets
Delivers real-time insights
Integrates with data center
Scalable and affordable
T U R N A L L O F Y O U R D ATA I N T O VA L U E
| Hadoop and the Hadoop elephant logo are trademarks of the Apache Software Foundation
Page 6
Page 7 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Two Paths in a Customer’s Journey to a Data LakeS
CA
LE
SCOPE
Goal:• Centralized Architecture• Data-driven Business
DATA LAKE
Journey to the Data Lake with Hadoop
Systems of Insight
The journey begins with either:
1. Cost Optimization (Data Architecture Optimization)
2. Advanced Analytic Applications
Leaders are Data Driven
Advanced Analytic Apps
Cost Optimization
Page 7
Page 9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop Ecosystem
runs on
ETL
RDBMS Import/Export
Distributed Storage & Processing Framework
Secure NoSQL DB
SQL on HBase
NoSQL DB
Workflow Management
SQL
Streaming Data Ingestion
Cluster System Operations
Secure Gateway
Distributed Registry
ETL
Search & Indexing
Even Faster Data Processing
Data Management
Machine Learning
Page 8
Page 10 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop Architecture
Data Access Engines
Distributed Reliable Storage
Distributed Compute FrameworkResource Mgt, Data Locality
Data Operating System
Batch Interactive Streaming
Governance Security
Apps
Page 9
Page 11 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop Key Services
Hortonworks Data Platform
Multi-tenant data platform built on a centralized architecture of shared enterprise services
YARN: data operating system
Governance Security
Operations
Resource management
Existing applications
Newanalytics
Partner applications
Data access: batch, interactive, real-time
Storage
Key Services
Resource and workload management
Scalable tiered storage
Consistent operations
Comprehensive security
Trusted data governance
Page 10
Page 12 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
HORTONWORKS DATA PLATFORM
H
ad
oo
p &
Y
AR
N
HDP 2.3 is Apache Hadoop; not “based on” Hadoop
DATA MGMT DATA ACCESS GOVERNANCE & INTEGRATION OPERATIONS SECURITY
HDP 2.2Dec 2014
HDP 2.1April 2014
HDP 2.0Oct 2013
HDP 2.2Dec 2014
HDP 2.1April 2014
HDP 2.0Oct 2013
2.2.0
2.4.0
2.6.0
HDP 2.3July 2015
2.7.1
Ongoing Innovation in Apache
HDFSYARNMapReduceHadoop Core
Page 11
Page 13 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
HORTONWORKS DATA PLATFORM
H
ad
oo
p &
Y
AR
N
HDP 2.3 is Apache Hadoop; not “based on” Hadoop
F
lum
e
O
ozi
e
P
ig
H
ive
Te
z
S
qo
op
C
lou
db
rea
k
A
mb
ari
S
lid
er
K
afk
a
K
no
x
S
olr
Z
oo
keep
er
S
pa
rk
F
alc
on
R
an
ge
r
H
Ba
se
A
tla
s
A
cc
um
ulo
S
torm
P
ho
en
ix
4.10.2
DATA MGMT DATA ACCESS GOVERNANCE & INTEGRATION OPERATIONS SECURITY
HDP 2.2Dec 2014
HDP 2.1April 2014
HDP 2.0Oct 2013
HDP 2.2Dec 2014
HDP 2.1April 2014
HDP 2.0Oct 2013
0.12.0 0.12.0
0.12.1 0.13.0 0.4.0
1.4.4 1.4.4 3.3.23.4.5
0.4.00.5.0
0.14.0 0.14.0 3.4.6 0.5.0 0.4.00.9.30.5.2
4.0.04.7.2
1.2.1 0.60.0 0.98.4 4.2.0 1.6.1 0.6.0 1.5.21.4.5 4.1.02.0.0
1.4.0 1.5.1 4.0.0
1.3.1
1.5.1 1.4.4 3.4.5
2.2.0
2.4.0
2.6.0
0.96.1
0.98.0 0.9.1
0.8.1
HDP 2.3July 2015
1.3.12.7.1 1.4.6 1.0.0 0.6.0 0.5.02.1.00.8.2 3.4.61.5.25.2.1 0.80.0 1.1.1 0.5.01.7.04.4.0 0.10.0 0.6.10.7.01.2.10.15.0 4.2.0
Ongoing Innovation in Apache
Page 12
Page 14 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hortonworks Development Investment for the Enterprise
Horizontal Integration for Enterprise ServicesEnsure consistent enterprise services are applied across the Hadoop stack
Vertical Integration with YARN and HDFS
Ensure engines can run reliably and respectfully in a YARN based cluster
Provision, Manage & Monitor
AmbariZookeeper
Scheduling
Oozie
Load data and manage
according to policy
Provide layered approach to
security through Authentication, Authorization,
Accounting, and Data Protection
SECURITYGOVERNANCE
Deploy and effectively
manage the platform
° ° ° ° ° ° ° ° ° ° ° ° ° ° °
Script
Pig
SQL
Hive
JavaScala
Cascading
Stream
Storm
Search
Solr
NoSQL
HBaseAccumulo
BATCH, INTERACTIVE & REAL-TIME DATA ACCESS
In-Memory
Spark
Others
ISV Engines
1 ° ° ° ° ° ° ° ° ° ° ° ° ° °
YARN: Data Operating System(Cluster Resource Management)
HDFS (Hadoop Distributed File System)
Tez Slider SliderTez Tez
OPERATIONS
Page 13
Page 15 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
`
+/directory/structure/in/memory.txt
Resource management + schedulingDisk, CPU, Memory
CoreNameNode
HDFS
ResourceManagerYARN
Hadoop daemon
User application
NN
RM
DataNodeHDFS
NodeManagerYARN
Worker Node
Page 14
Page 16 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Joys of Real Hardware (Jeff Dean)
Typical first year for a new cluster:~0.5 overheating (power down most machines in <5 mins, ~1-2 days to recover)~1 PDU failure (~500-1000 machines suddenly disappear, ~6 hours to come back)~1 rack-move (plenty of warning, ~500-1000 machines powered down, ~6 hours)~1 network rewiring (rolling ~5% of machines down over 2-day span)~20 rack failures (40-80 machines instantly disappear, 1-6 hours to get back)~5 racks go wonky (40-80 machines see 50% packetloss)~8 network maintenances (4 might cause ~30-minute random connectivity losses)~12 router reloads (takes out DNS and external vips for a couple minutes)~3 router failures (have to immediately pull traffic for an hour)~dozens of minor 30-second blips for dns~1000 individual machine failures~thousands of hard drive failuresslow disks, bad memory, misconfigured machines, flaky machines, etc
Page 15
Page 17 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop Distributed File System (HDFS)
Fault Tolerant Distributed Storage
• Divide files into big blocks and distribute 3 copies randomly across the cluster
• Processing Data Locality
• Not Just storage but computation
10110100101001001110011111100101001110100101001011001001010100110001010010111010111010111101101101010110100101010010101010101110010011010111
0100
Logical File
1
2
3
4
Blocks
1
Cluster
1
1
2
22
3
3
34
44
Page 16
Page 18 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
The DataNodes
“I’m still here! This is my latest heartbeat.”
“I’m here too! And here is my latest heartbeat.”
123
“Hey DataNode1, Replicate block 123 to
DataNode 3.”
NameNode
DataNode 1 DataNode 3 DataNode 4
123 123
DataNode 1
Page 17
Page 19 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Batch Processing in Hadoop
MapReduceBatch Access to DataOriginal data access mechanism for Hadoop
• FrameworkMade for developing distributed applications to process vast amounts of data in-parallel on large clusters
• ProvenReliable interface to Hadoop which works from GB to PB. But, batch oriented – Speed is not it’s strong point.
• EcosystemPorted to Hadoop 2 to run on YARN. Supports original investments in Hadoop by customers and partner ecosystem.
DataNode1
Mapper
Data is shuffledacross the network
& sorted
Map Phase
Shuffle/Sort Reduce Phase
MapReduce Job Lifecycle
Saying that MapReduce is dead is preposterous- Would limits us to only new workloads
- ALL Hadoop clusters use map reduce
- Why rewrite everything immediately?
DataNode2
Mapper
DataNode3
Mapper
DataNode1
Reducer
DataNode2
Reducer
DataNode3
Reducer
YARN: Data Operating System
Interactive Real-TimeBatch
Page 18
Page 20 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What is MapReduce?
Break a large problem into sub-solutionsMap
• Iterate over a large # of records
• Extract something of interest from each record
Shuffle
• Sort Intermediate results
Reduce
• Aggregate, summarize, filter or transform intermediate results
• Generate final output
Map Process
Map Process
Map Process
Map Process
Data
DataData
Data
DataData
Data
Data
DataData
Data
DataData Map
Process
Reduce Process
Reduce Process
Data
Read & ETL
Shuffle & SortAggregation
Data
DataData
Data
Data
Data
Data
Data
Page 19
Page 22 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
1st Gen Hadoop: Cost Effective Batch at Scale
HADOOP 1.0Built for Web-Scale Batch Apps
Single App
BATCH
HDFS
Single App
INTERACTIVE
Single App
BATCH
HDFS
Silos created for distinct use casesSingle App
BATCH
HDFS
Single App
ONLINE
Page 20
Page 23 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop emerged as foundation of new data architecture
Apache Hadoop is an open source data platform for managing large volumes of high velocity and variety of data
• Built by Yahoo! to be the heartbeat of its ad & search business
• Donated to Apache Software Foundation in 2005 with rapid adoption by large web properties & early adopter enterprises
• Incredibly disruptive to current platform economics
Traditional Hadoop Advantages Manages new data paradigm Handles data at scale Cost effective Open source
Traditional Hadoop Had Limitations
Batch-only architecture
Single purpose clusters, specific data sets
Difficult to integrate with existing investments
Not enterprise-grade
Application
StorageHDFS
Batch ProcessingMapReduce
Page 21
Page 24 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What does iOS 6 and Windows 3.1 have in common?
Page 22
Page 26 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop Beyond Batch with YARN
HDFS
MapReduce
Pig(data flow)
Hive(SQL)
OthersAPI,
Engine, andSystem
Hadoop 1MapReduce as the Base
HDFS(redundant, reliable storage)
YARN(Data Operating System: resource management, etc.)
Tez(modern execution engine)
Data FlowPig
SQLHive
Java AppsCascading
BatchMapReduce
Hadoop 2Apache Yarn as a Base
System
Engine
API’s
Single Use SysztemBatch Apps
Multi Use Data PlatformBatch, Interactive, Online, Streaming, …
A shift from the old to the new…
Page 23
Page 27 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Tez is a critical innovation of the Stinger Initiative.
• Along with YARN, Tez not only improves Hive, but improves all things batch and interactive for Hadoop; Pig, Cascading…
• More Efficient Processing than MapReduce
• Reduce operations and complexity of back end processing• Allows for Map Reduce Reduce which saves hard disk operations• Implements a “service” which is always on, decreasing start times
of jobs• Allows Caching of Data in Memory
YARN
Dev
Cascading/Scalding
Why is Tez Important?
°1 ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°°
° ° ° ° ° ° °
° ° ° ° ° ° N
HDFS (Hadoop Distributed File
System)
Scripting
Pig
SQL
Hive
Tez Tez
Applications
Tez
YARN: Data Operating System
Interactive Real-TimeBatch
Page 24
Page 28 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Tez
Hive – MapReduce Hive – Tez
SELECT a.state, COUNT(*), AVG(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
SELECT a.state
JOIN (a, c)SELECT c.price
SELECT b.id
JOIN(a, b)GROUP BY a.state
COUNT(*)AVG(c.price)
M M M
R R
M M
R
M M
R
M M
R
HDFS
HDFS
HDFS
M M M
R R
R
M M
R
R
SELECT a.state,c.itemId
JOIN (a, c)
JOIN(a, b)GROUP BY a.state
COUNT(*)AVG(c.price)
SELECT b.id
Tez avoids unneeded writes to HDFS
Page 25
Page 29 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
HDP delivers a Centralized Architecture
YARN
Other Pure Play Vendors A siloed “with” YARN architecture
Disjoint, Siloed Clusters• Inefficient use of resources, single tenant, duplicate storage & processing
• Multiple implementations of governance, security and operations
• New applications require new clusters
Hortonworks Data PlatformA centralized architecture built on YARN
Clu
ste
r 1
Application
Security
Storage
YARN
Governance
Operations
Batch
Storage
YARN: Data Operating System
Governance Security
Operations
Resource Management
Existing Applications
NewAnalytics
Partner Applications
(ie. SAS)
Clu
ste
r 2
Application
Security
Storage
Governance
Operations
Clu
ste
r N
Application
Security
Storage
Governance
Operations
…
Interactive
Dedicated Resource mgt
Real-time
Dedicated Resource mgt
Single cluster, multiple applications• Efficient storage, processing
• Centralized Security, Operations, Governance
• Run a variety of applications simultaneously
Data Access: Batch, Interactive & Real-time
Page 26
Page 30 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
{Processing + Storage}
={MapReduce/YARN + HDFS}
={Core Hadoop}
Page 27
Page 31 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Modern Data Architecture emerges to unify data & processing
Modern Data Architecture
• Enable applications to have access to all your enterprise data through an efficient centralized platform
• Supported with a centralized approach governance, security and operations
• Versatile to handle any applications and datasets no matter the size or type
Clickstream Web & Social
Geolocation Sensor & Machine
Server Logs
Unstructured
SO
UR
CE
S
Existing Systems
ERP CRM SCM
AN
ALY
TIC
S
Data Marts
Business Analytics
Visualization& Dashboards
AN
ALY
TIC
S
ApplicationsBusiness Analytics
Visualization& Dashboards
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
HDFS (Hadoop Distributed File System)
YARN: Data Operating System
Interactive Real-TimeBatch Partner ISVBatch BatchMPP
EDW
Page 28
Page 32 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What is Data Access?
Data Access defines ALL the channels through which data can be accessed,
analyzed, cleansed and consumed within Hadoop. Each channel can be
categorized into THREE core patterns; Batch, Interactive and Real-time.
Multiple engines provide optimized access to your
mission critical data.
Page 29
Page 33 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
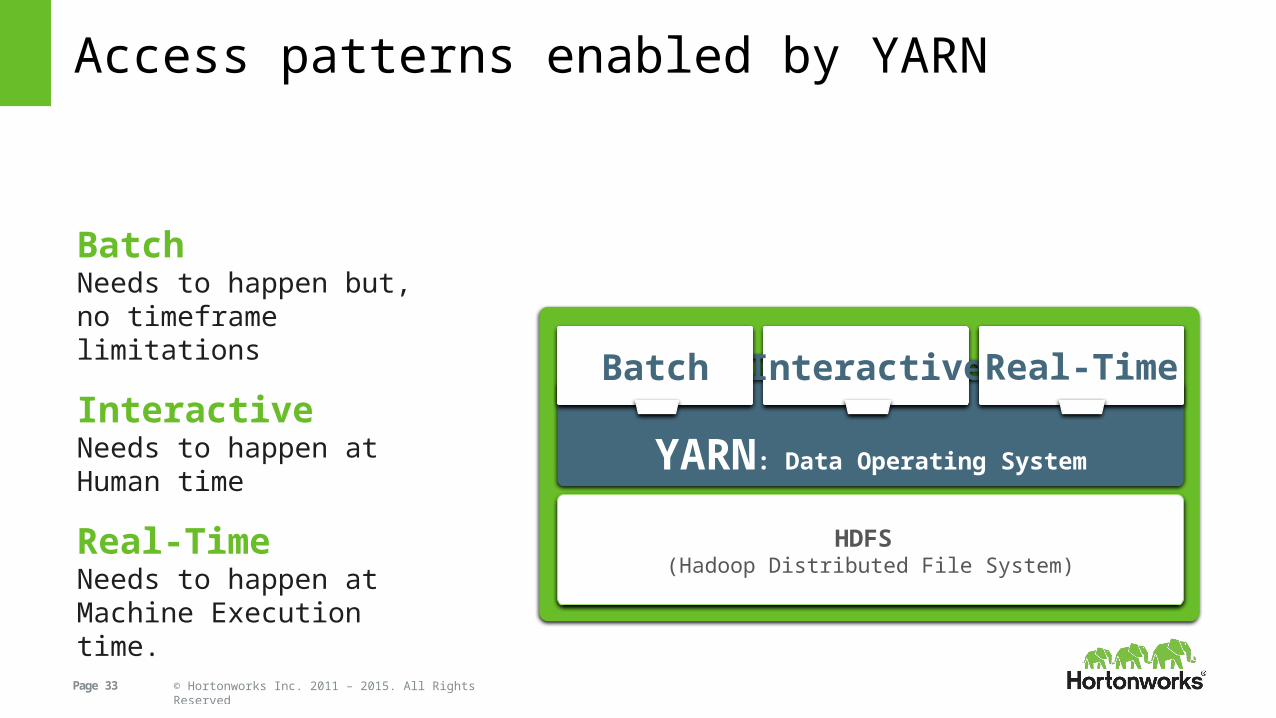
Access patterns enabled by YARN
BatchNeeds to happen but, no timeframe limitations
Interactive Needs to happen at Human time
Real-Time Needs to happen at Machine Execution time.
YARN: Data Operating System
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°N
HDFS (Hadoop Distributed File System)
Interactive Real-TimeBatch
Page 30
Page 34 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Projects Enable Access Patterns
• Various Open Source projects have incubated in order to meet these access pattern needs
• Today, they can all run on a single cluster on a Single set of data because of YARN!
• ALL powered by a BROAD Open Community
YARN: Data Operating System
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°N
HDFS (Hadoop Distributed File System)
BatchMapReduce
PigHive
InteractiveSolr
SparkHive
Kafka
Real-TimeHBase
AccumuloStorm
Page 31
Page 35 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Scripting Data Flow & ETLApache Pig
• Data flow engine and scripting language (Pig Latin)
• Allows you to transform data and datasets
Advantages over MapReduce• Reduces time to write jobs
• Community support
• Piggybank has a significant number of UDF’s to help adoption
• There are a large number of existing shops using PIG
YARN: Data Operating System
Interactive Real-TimeBatch
Page 32
Page 36 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Pig Latin
• Pig executes in a unique fashion:oDuring execution, each statement is processed by the Pig
interpreter o If a statement is valid, it gets added to a logical plan built by the
interpretero The steps in the logical plan do not actually execute until a
DUMP or STORE command is used
Page 33
Page 37 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Why use Pig?
• Maybe we want to join two datasets, from different sources, on a common value, and want to filter, and sort, and get top 5 sites
Page 34
Page 38 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Hive: THE defacto standard for SQL in Hadoop
• What?
• Treat your data in Hadoop as tables
• Provides a standard SQL 92 interface to data in Hadoop
• Why?
• Shipped in every distribution… you already have it (although some do not ship complete versions) Quickly find value in raw data files
• Proven at petabyte scale for both batch and interactive queries
• Compatible with ALL major BI tools such as Tableau, Excel, MicroStrategy, Business Objects, etc…
Page 35
Page 39 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive Architecture
User issues SQL query
Hive parses and plans query
Query converted to MapReduce/Tez and executed on Hadoop
2
3
Web UI
JDBC / ODBC
CLI
HiveSQL
1
1HiveServer2 Hive
MR/Tez Compiler
Optimizer
Executor
2
Hive
MetaStore(MySQL, Postgresql,
Oracle)
MapReduce or Tez Job
Data DataData
Hadoop 3Data-local processing
Page 36
Page 40 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Using Tez for Hive Queries
Set the following property in either hive-site.xml or in your script:
set hive.execution.engine=tez;
Page 37
Page 41 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
SQL ComplianceEvolution of SQL Compliance in HiveSQL Datatypes SQL Semantics
INT/TINYINT/SMALLINT/BIGINT SELECT, INSERT
FLOAT/DOUBLE GROUP BY, ORDER BY, HAVING
BOOLEAN JOIN on explicit join key
ARRAY, MAP, STRUCT, UNION Inner, outer, cross and semi joins
STRING Sub-queries in the FROM clause
BINARY ROLLUP and CUBE
TIMESTAMP UNION
DECIMAL Standard aggregations (sum, avg, etc.)
DATE Custom Java UDFs
VARCHAR Windowing functions (OVER, RANK, etc.)
CHAR Advanced UDFs (ngram, XPath, URL)
Interval Types Sub-queries for IN/NOT IN, HAVING
JOINs in WHERE Clause
INSERT/UPDATE/DELETE
Legend
Hive 10 or earlier
Roadmap
Hive 11
Hive 12
Hive 13
YARN: Data Operating System
Interactive Real-TimeBatch
Page 38
Page 42 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Overview of Stinger
Base OptimizationsGenerate simplified DAGs
In-memory Hash Joins
Vector Query EngineOptimized for modern processor
architectures
TezExpress tasks more simply
Eliminate disk writesPre-warmed Containers
ORCFileColumn Store
High CompressionPredicate / Filter Pushdowns
YARNNext-gen Hadoop data processing
framework
100X+ Faster Time to Insight
+ +
Deeper Analytical Capabilities
Performance Optimizations
Query PlannerIntelligent Cost-Based Optimizer
Page 39
Page 43 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
System
Engine
API
YARN : Data Operating System
°1 ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°°
° ° ° ° ° ° °
° ° ° ° ° ° N
HDFS (Hadoop Distributed File System)
BatchMapReduce
Real-TimeSlider
Direct
Java.NET
Scripting
Pig
SQL
Hive
Cascading
JavaScala
NoSQL
HBaseAccumulo
Stream
Storm
OtherISV
OtherISV
Applications
Others
Spark Other ISV
HDP 2.2 HDP 2.2
HDP 2.2 HDP 2.2
HDP 2.2TezTezTez Tez
YARN: Resource Manager for Hadoop 2.0
FlexibleEnables other purpose-built data processing models beyond MapReduce (batch), such as interactive and streaming
EfficientDouble processing IN Hadoop on the same hardware while providing predictable performance & quality of service
SharedProvides a stable, reliable, secure foundation and shared operational services across multiple workloads
Data Processing Engines Run Natively IN Hadoop
Page 40
Page 44 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive & Pig
Hive & Pig work well together and many customers use both
Hive is a good choice:
• if you are familiar with SQL
• when you want to query data
• when you need an answer to specific questions
Pig is a good choice:
• For ETL (Extract, Transform, Load)
• for preparing data for analysis
• when you have a long series of steps to perform
YARN: Data Operating System
Interactive Real-TimeBatch
Page 41
Page 45 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Pig and Hive Sample Scenario
Hadoop DistributedFile System
StructuredData
RawData
1. Put the data into HDFS in its raw format
Answers to questions = $$
2. Use Pig to explore andtransform
3. Data analysts use Hive to query the data
4. Data scientists use MapReduce, R, Mahout and Spark to mine the data
Hidden gems = $$
Page 42
Page 46 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Big Data ETL Life Cycle
Mobile Apps
Transactions,OLTP, OLAP
Social Media, Web Logs
Machine Device, Scientific
Documents and Emails
9. Govern & enrich with metadata
3. Stream real-time data
8. Explore & validate data
4. Mask sensitive data
2. Replicate changed data & schemas
Visualization& Analytics
11. Subscribe to datasets
Data Mart
1. Load or archive batch data
Data Access & Query
5. Access customer “golden record
MDM
10. Correlate real-time events with historical patterns & trends
6. Transform & refine data
7. Move results to EDW
Page 43
Page 47 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
HDP: Any Data, Any Application, Anywhere
Any Application
• Deep integration with ecosystem partners to extend existing investments and skills
• Broadest set of applications through the stable of YARN-Ready applications
Any DataDeploy applications fueled by clickstream, sensor, social, mobile, geo-location, server log, and other new paradigm datasets with existing legacy datasets.
AnywhereImplement HDP naturally across the complete range of deployment options
Clickstream Web & Social
Geolocation Internet of Things
Server Logs
Files, emailsERP CRM SCM
hybrid
commodity appliance cloud
Over 70 Hortonworks Certified YARN Apps
Page 44
Page 48 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What next? -> developer.hortonworks.com
Page 45
Page 49 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Thank you!
[email protected]
@racoss
Page 46
Page 50 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
IoT Data Discovery Lab
• A trucking company has over 100 trucks.• The geolocation data collected from the trucks contains events generated
while the truck drivers are driving.• The company’s goal with Hadoop is to Mitigate Risk:
o Understand correlations between miles driven and eventso Compute the risk factor for each driver based on mileage & events
o Lab Envo Sandbox 2.3 TP
o Lab Doco URL: http://ow.ly/Qv1JMo Load Datao Query Datao Process Data
Page 47
Page 51 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
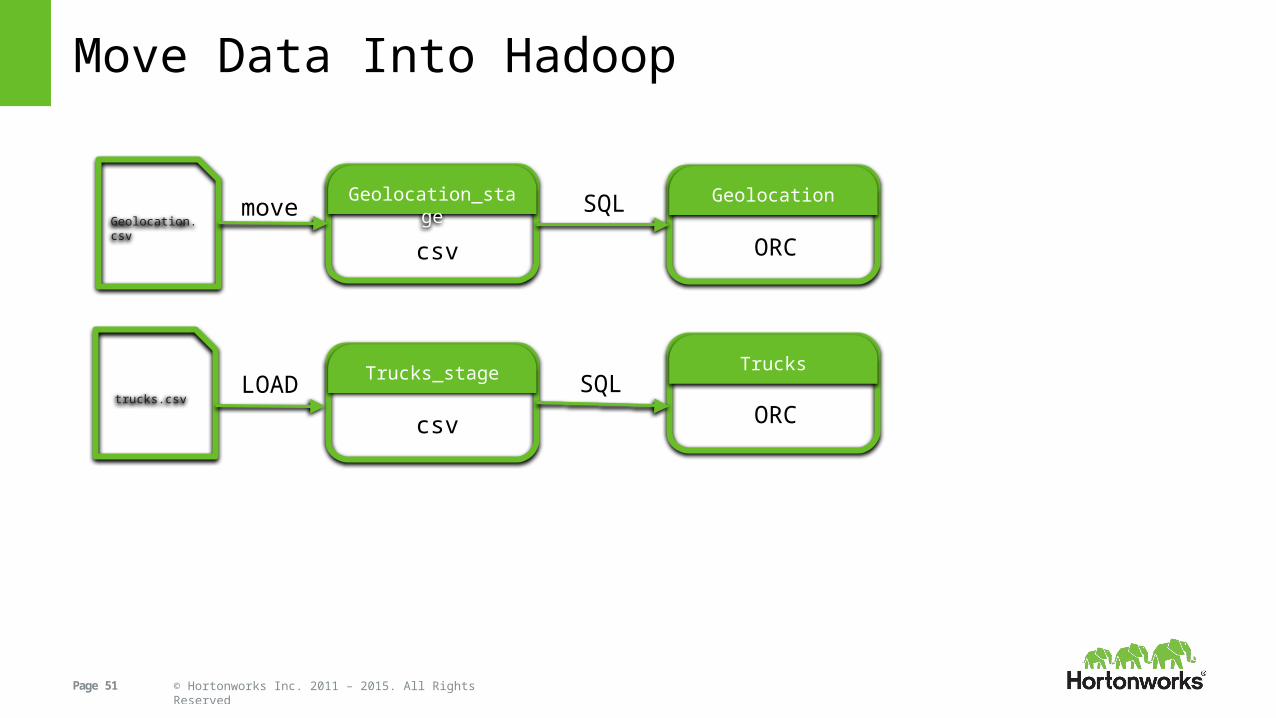
Move Data Into Hadoop
Geolocation.csv
trucks.csv
Geolocation_stage Geolocation
Trucks_stage Trucks
csv
csv ORC
ORC
SQL
SQL
move
LOAD
Page 48
Page 52 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Geolocation
Trucks
ORC
ORC
SQL
SQL
PIGRisk Calculation
Truck_mileage
ORC
Avg_mileage
ORC
DriverMileage
ORC
RiskFactor
ORC
Events
ORC
Trucking Risk Analysis – Hadoop ELT
Page 49
Page 53 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Calculate Risk
Page 50
Page 54 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Cautionary Statement Regarding Forward-Looking Statements
This presentation contains forward-looking statements involving risks and uncertainties. Such forward-looking statements in this presentation generally relate to future events, our ability to increase the number of support subscription customers, the growth in usage of the Hadoop framework, our ability to innovate and develop the various open source projects that will enhance the capabilities of the Hortonworks Data Platform, anticipated customer benefits and general business outlook. In some cases, you can identify forward-looking statements because they contain words such as “may,” “will,” “should,” “expects,” “plans,” “anticipates,” “could,” “intends,” “target,” “projects,” “contemplates,” “believes,” “estimates,” “predicts,” “potential” or “continue” or similar terms or expressions that concern our expectations, strategy, plans or intentions. You should not rely upon forward-looking statements as predictions of future events. We have based the forward-looking statements contained in this presentation primarily on our current expectations and projections about future events and trends that we believe may affect our business, financial condition and prospects. We cannot assure you that the results, events and circumstances reflected in the forward-looking statements will be achieved or occur, and actual results, events, or circumstances could differ materially from those described in the forward-looking statements.
The forward-looking statements made in this prospectus relate only to events as of the date on which the statements are made and we undertake no obligation to update any of the information in this presentation.
TrademarksHortonworks is a trademark of Hortonworks, Inc. in the United States and other jurisdictions. Other names used herein may be trademarks of their respective owners.
Page 51
Page 55 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
A Definition of Open Enterprise Hadoop
Provision, Manage & Monitor
AmbariZookeeper
Scheduling
Oozie
Load data and manage
according to policy
Provide layered approach to
security through Authentication, Authorization,
Accounting, and Data Protection
SECURITYGOVERNANCE
Deploy and effectively
manage the platform
° ° ° ° ° ° ° ° ° ° ° ° ° ° °
BATCH, INTERACTIVE & REAL-TIME DATA ACCESS
YARN: Data Operating System(Cluster Resource Management)
HDFS (Hadoop Distributed File System)
OPERATIONS
Batch Interactive Real-Time
Page 52
Page 56 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Big Data ETL Life Cycle
Mobile Apps
Transactions,OLTP, OLAP
Social Media, Web Logs
Machine Device, Scientific
Documents and Emails
9. Govern & enrich with metadata
3. Stream real-time data
8. Explore & validate data
4. Mask sensitive data
2. Replicate changed data & schemas
Visualization& Analytics
11. Subscribe to datasets
Data Mart
1. Load or archive batch data
Data Access & Query
5. Access customer “golden record
MDM
10. Correlate real-time events with historical patterns & trends
6. Transform & refine data
7. Move results to EDW
Page 53
Page 57 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
EDW
DataDataData
DataData
Data
Data DataDataSchemaData
DataData
ETL ETL
ETL ETL
EDW
DataDataData
DataData
Data
Data DataDataSchemaData
DataData
ETL ETL
ETL ETL
Fragile workflows make supporting the analytical models you want expensive and time-consuming.
Page 54
Page 58 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Options for Data Input
MapReduce
WebHDFShadoop fs -put
Vendor Connectors
Hadoop
nfs gateway
Hue Explorer
Page 55
Page 59 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Risk Factors Viewed in a Graph
Page 56
Page 60 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Risk Factors Viewed on a Map