42
Runtime Optimization of Join Location in Parallel Data Management Systems Bikash Chandra, S. Sudarshan CSE Department, IIT Bombay Work supported by a PhD fellowship from TCS
| Date post: | 15-Apr-2017 |
| Category: |
Technology |
| Upload: | datatorrent |
| View: | 7 times |
| Download: | 0 times |

Runtime Optimization of Join Location in Parallel Data
ManagementSystems
Bikash Chandra, S. Sudarshan
CSE Department,IIT Bombay
Work supported by a PhD fellowship from TCS

Parallel Data Management Systems
● Batch Processing Systems− Hadoop, SCOPE, Hyracks, Spark
● Stream Dataflow− Apex, Storm, S4, Muppet, Kinesis, Samza, MillWheel
● Typically process one tuple at a time, may read and update some state and emit tuples
● Lookups on remote site or disk is slow, hence avoided

● Motivating Applications● General Framework● Frequency Based Optimizations● Load Balancing● Related Work● Experimental Results
Outline
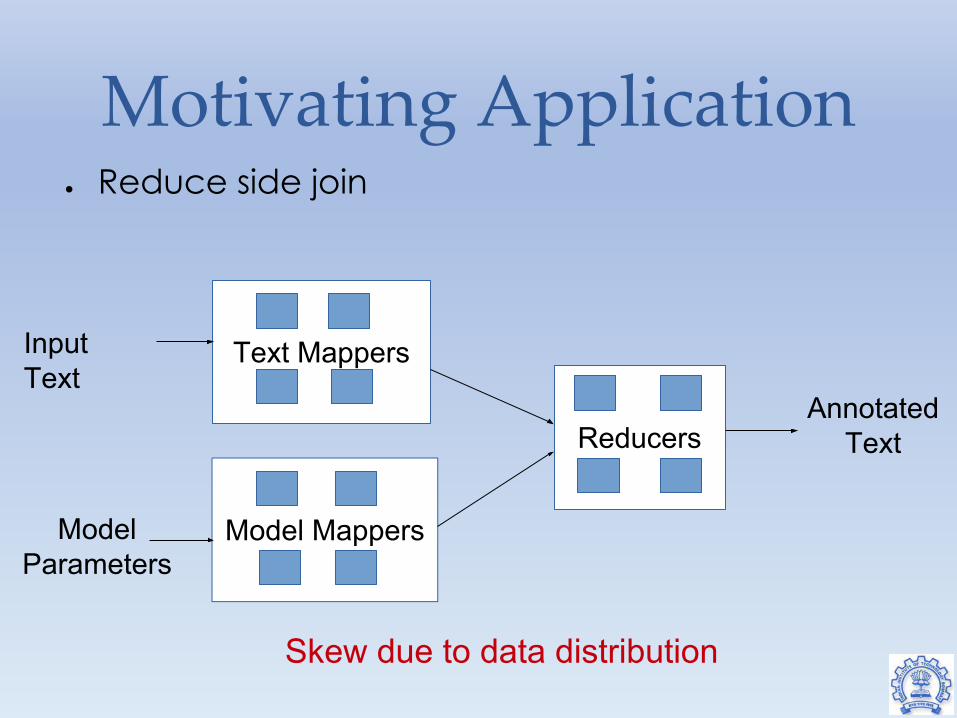
Motivating Application● Reduce side join
Model Mappers
Text Mappers
Reducers
Input Text
ModelParameters
Annotated Text
Skew due to data distribution
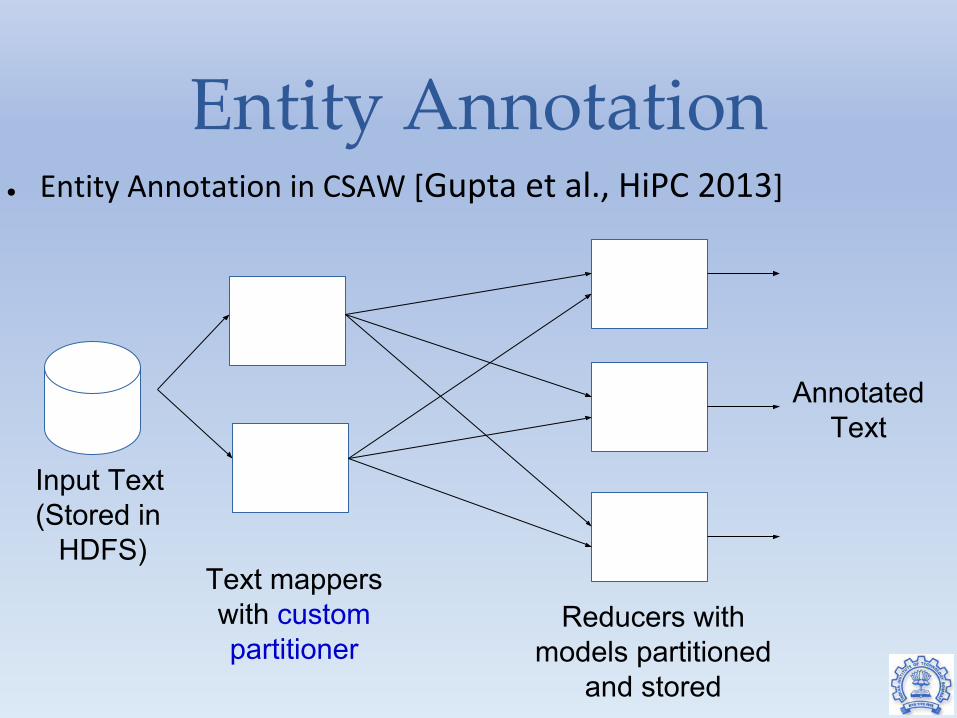
Entity Annotation● Entity Annotation in CSAW [Gupta et al., HiPC 2013]
Input Text(Stored in
HDFS)Text mappers with custom partitioner
Reducers with models partitioned
and stored
Annotated Text
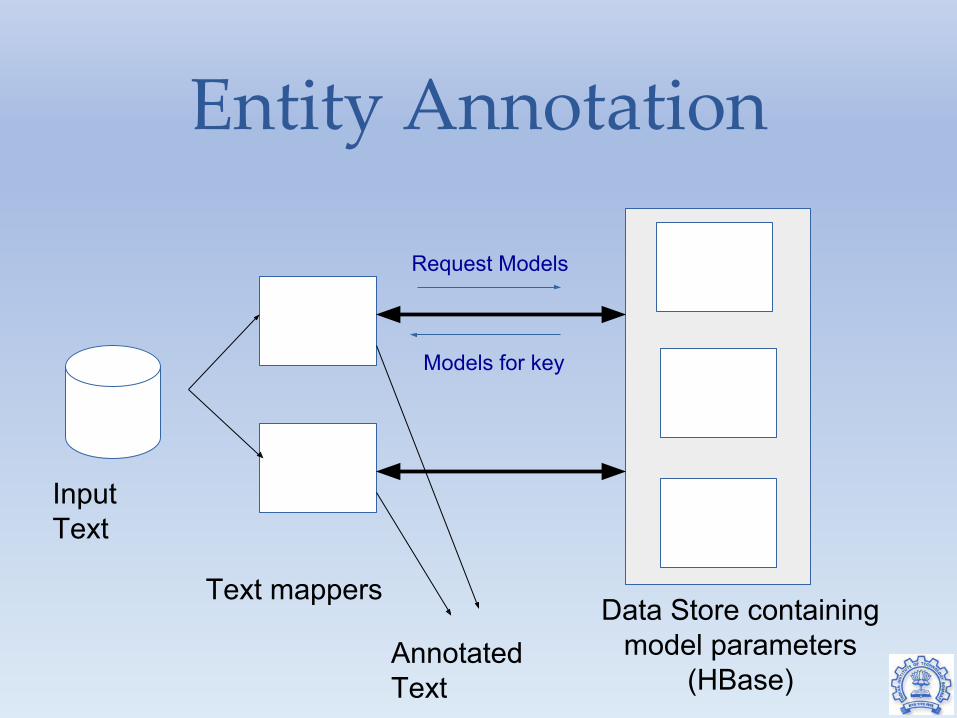
Entity Annotation
Input Text
Text mappers Data Store containing
model parameters (HBase)
Annotated Text
Request Models
Models for key

Other Motivating Applications
● Stream-relation join
● SSIJ [Bornea et al. ICDE 2011]● MeshJoin [Polyzotis et al. ICDE 2007]
● Genome read mapping● Align a set of genome sequence reads with a reference
sequence.● Parameters server framework for efficient distributed machine
learning● Use HBase to store machine learning models

● Motivating Applications● General Framework● Frequency Based Optimizations● Load Balancing● Related Work● Experimental Results
Outline
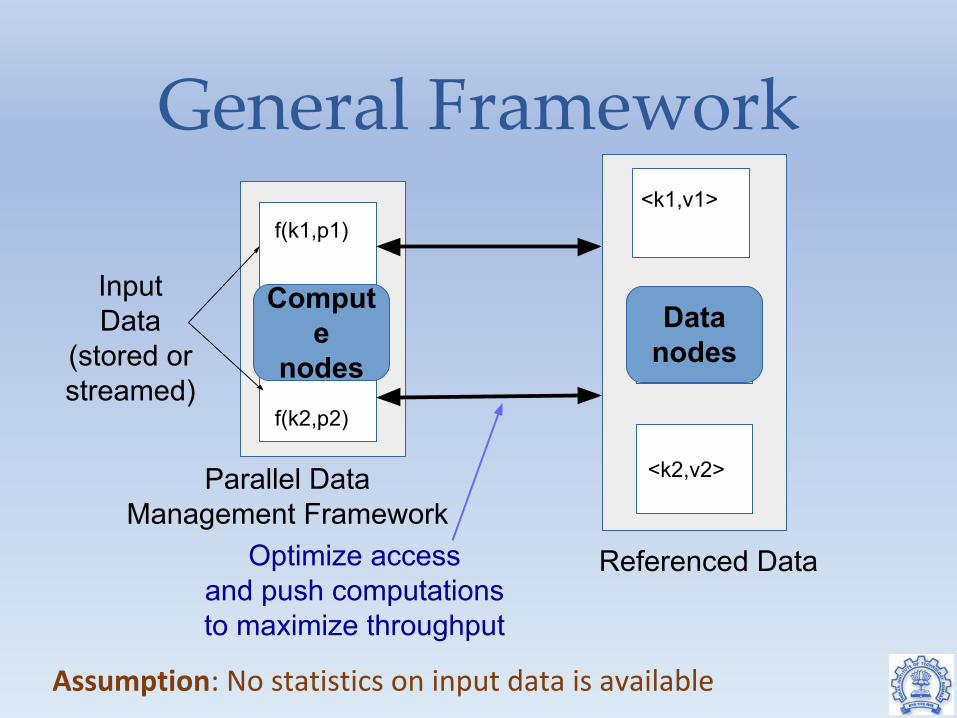
General Framework
Input Data
(stored or streamed)
Parallel Data Management Framework
Referenced DataOptimize access and push computations to maximize throughput
Compute
nodes
Data nodes
f(k1,p1)
f(k2,p2)
<k2,v2>
<k1,v1>
Assumption: No statistics on input data is available

Computation Alternatives● f (k, p) can be invoked in many ways
1) For each ki fetch the stored value v
i at the compute node,
invoke function at compute node
2) Send values (ki, p
i ) to the node storing the record with
value ki , and compute the function at the data node
∙ Endpoints in HBase
3) Decide on 1 or 2 dynamically based on number of invocations for k
i and the load
4) Send each request individually or in batches

f(key,params) { model = modelStore.getModel(key) annotatedValues = classifyRecord(params,model) return annotatedValues
}
Examplemap(docId, document) {
for each spot in document.getSpots(){spotContext = getContextRecord(spot,document)
annotatedValues = f(spotContext.key,spotContext.value) context.write(spotContext.key, annotatedValues)
}}

Access Optimizations Issues● Accessing data items individually and synchronously is
expensive● Data processing frameworks process one data item at a time
Solutions● Modify framework to enable issuing prefetch requests in a
parallel thread ● Prefetch requests can be batched – batch sizes can be set
based on latency requirements
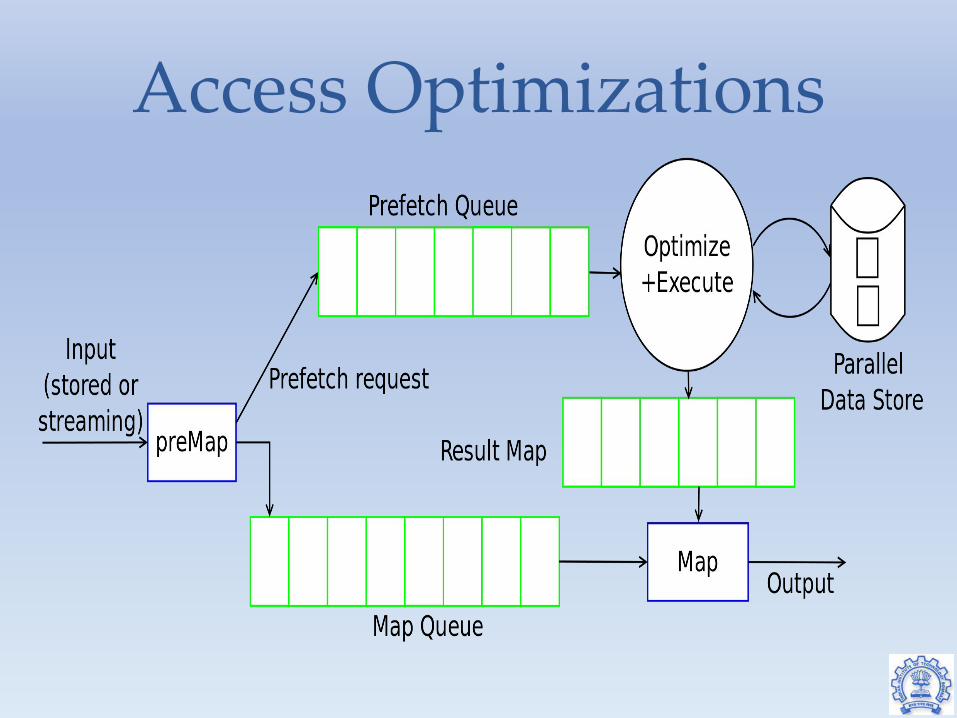
Access Optimizations

Transformed Code
● In map function, replace the function call by getComp(f,k,v)
preMap(documentId,document) {for each spot in document.getSpots() {
spotContext = getContextRecord(spot, document)
submitComp(f,spotContext.key,spotContext.value)
}mapQueue.add([documentId,document])
}

● Motivating Applications● General Framework● Frequency Based Optimizations● Load Balancing● Related Work● Experimental Results
Outline
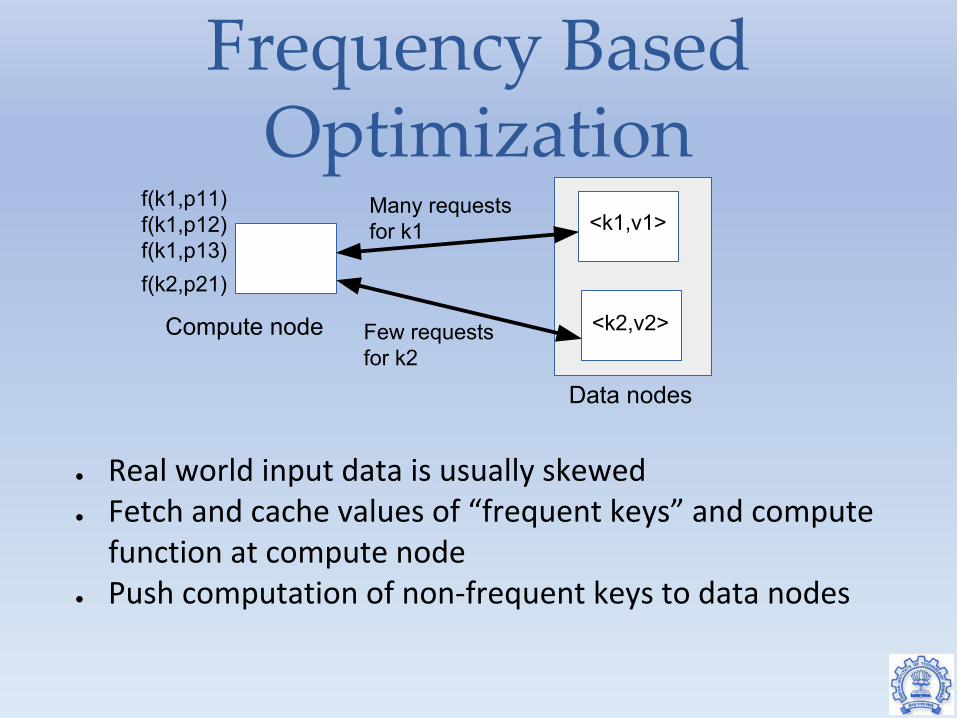
Frequency Based Optimization
● Real world input data is usually skewed● Fetch and cache values of “frequent keys” and compute
function at compute node● Push computation of non-frequent keys to data nodes
<k1,v1>f(k1,p11)f(k1,p12)f(k1,p13)
Few requests for k2
<k2,v2>
f(k2,p21)
Many requests for k1
Compute node
Data nodes

Classical ski-rental ● Karlin et. al – ACM-SIAM, 1990

Classical ski-rental● A skier goes on a trip where he can choose to rent a ski or
to buy it.
● Renting a ski has recurring costs each day while buying incurs a one time cost
● The number of days for the trip is not know in advance
● Goal – Minimize the total cost

Classical Ski-rental● Let − cost to rent per day be r− cost to buy be b
● Solution - keep renting for the first b/r times and then buy the object
● Cost is never more than twice the optimal cost. Competitive ratio - 2
● In our problem setting− Sending computations to data node - rent− Fetching data to compute node - buy

Limitations of Ski-rental● In classic ski-rental there is no recurring maintenance cost
after buying− Function needs to be computed even after caching – for
the same k the value of p in f(k,p) may change● Storage space is not taken into account− Cache may be limited. May not be able to keep all items
that have been bought● Skies do not break− Values in data store may get updated

Ski-rental with recurring cost
● Recurring cost after buying be br
● One should continue renting when (m is the number of accesses)
● Competitive ratio

Ski-rental with limited cache
● Items can be cached in memory or on disk
mcache (m bytes)
dcache (d bytes)
● Items that provide more benefit in memory and items that provide less benefit in disk
● Use weighted LFU-DA [Arlitt et al. SIGMETRICS 2000 ] for frequency based cache replacement with aging to compute benefit

Updates to data store● Data node items may get updated while the process is
running
● Treat updated items as new items● Set access count to 0● Ensures frequently updated items are not bought
● With each response to a compute request, the data node also sends the last updated timestamp
● Invalidate cache entries corresponding to updates key ki

Computing costs for ski rental
● Renting cost − max (Network cost, CPU cost at data node)
● Buying cost − Network cost to fetch v
● Recurring buying cost for item in memory cache − CPU cost at compute node
● Recurring buying cost for item in disk cache− max(CPU cost at compute node, disk read cost)

● Parallel Data Management Systems● Motivating Applications● General Framework● Frequency Based Optimizations● Load Balancing● Related Work● Experimental Results
Outline

Balancing Computations● Ski-rental based optimization may lead to overload the
data nodes
● Data node may− Compute function for some (k
i,p
i)
− For the remaining return the values necessary for computation to the compute node
● Disk cost to lookup item from data node is incurred in both cases
● Data node decides how many values to compute based on CPU and network costs
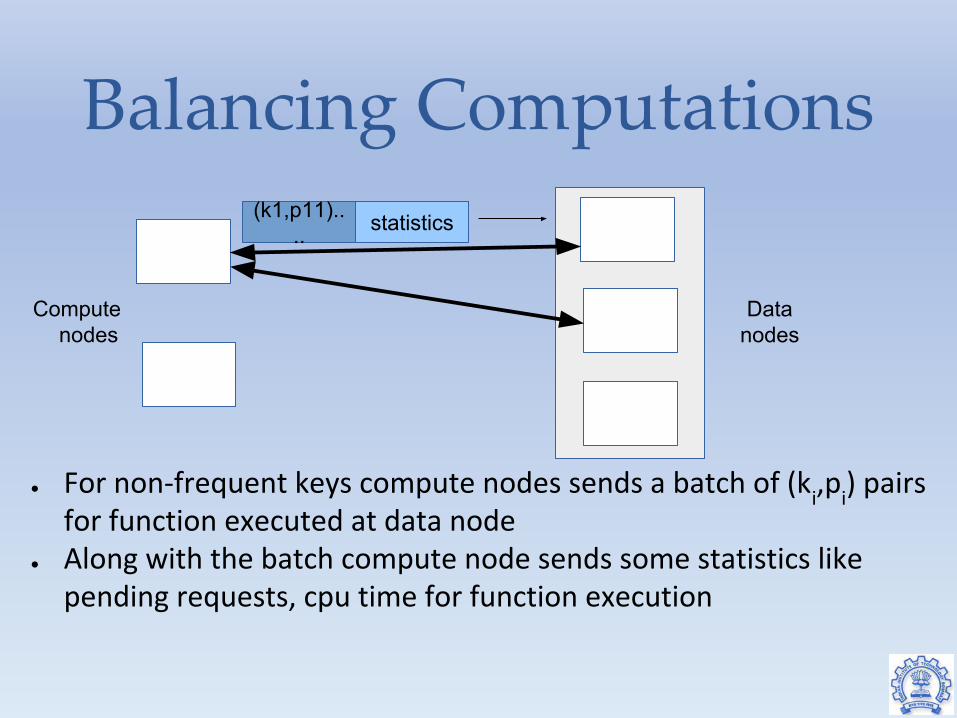
Balancing Computations
● For non-frequent keys compute nodes sends a batch of (ki,p
i) pairs
for function executed at data node● Along with the batch compute node sends some statistics like
pending requests, cpu time for function execution
(k1,p11).... statistics
Computenodes
Datanodes
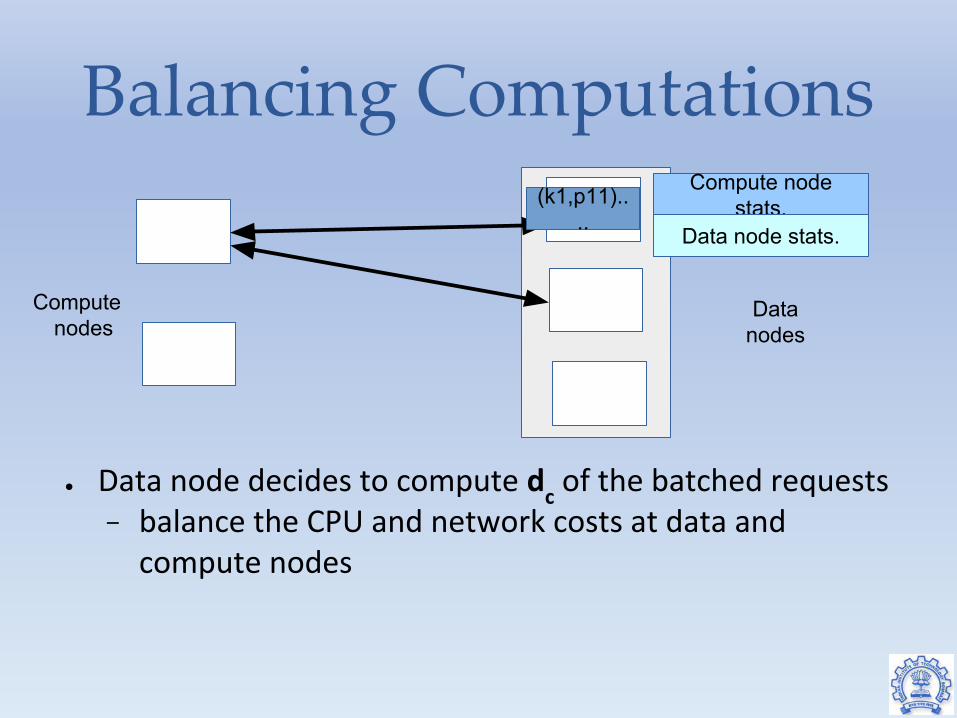
Balancing Computations
● Data node decides to compute dc of the batched requests
− balance the CPU and network costs at data and compute nodes
Compute node stats.
Data node stats.
(k1,p11)....
Computenodes
Datanodes
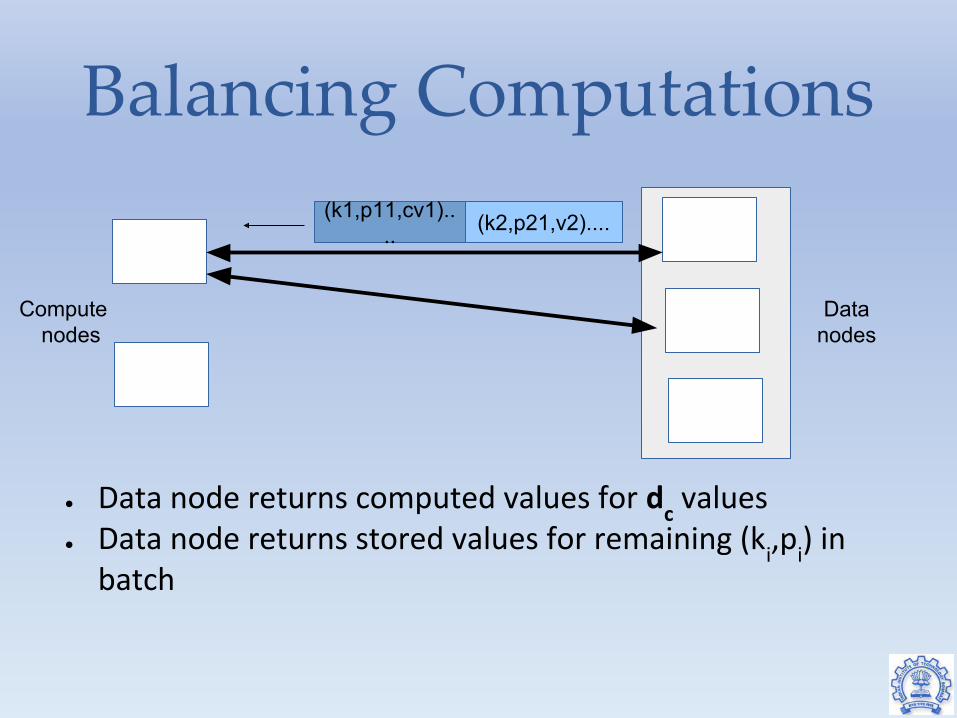
Balancing Computations
● Data node returns computed values for dc values
● Data node returns stored values for remaining (ki,p
i) in
batch
(k1,p11,cv1).... (k2,p21,v2)....
Computenodes
Datanodes

● Motivating Applications● General Framework● Frequency Based Optimizations● Load Balancing● Related Work● Experimental Results
Outline

Related Work● Stream Relation Join
● Join algorithms mostly rely on caching and/or nested loops join with batches of stream
● Skew Reducing Framework● Find heavy hitters based on statistics and broadcast those,
dynamic repartition
● Data access optimization● Pyxis - Transforms imperative code to run some code at
database server using stored procedures● DBridge – Uses batching and asynchronous prefetching for
database access

● Motivating Applications● General Framework● Frequency Based Optimizations● Load Balancing● Related Work● Experimental Results
Outline

Experimental Setup
● 20 node cluster
● 10 nodes as compute nodes and 10 nodes as data nodes
● Each node has 2 quad core Xeon L5420 CPUs and 16 GB RAM
● Memory cache size was limited to 100 MB in memory to consider the scenario that memory cache is not enough to store all cached items
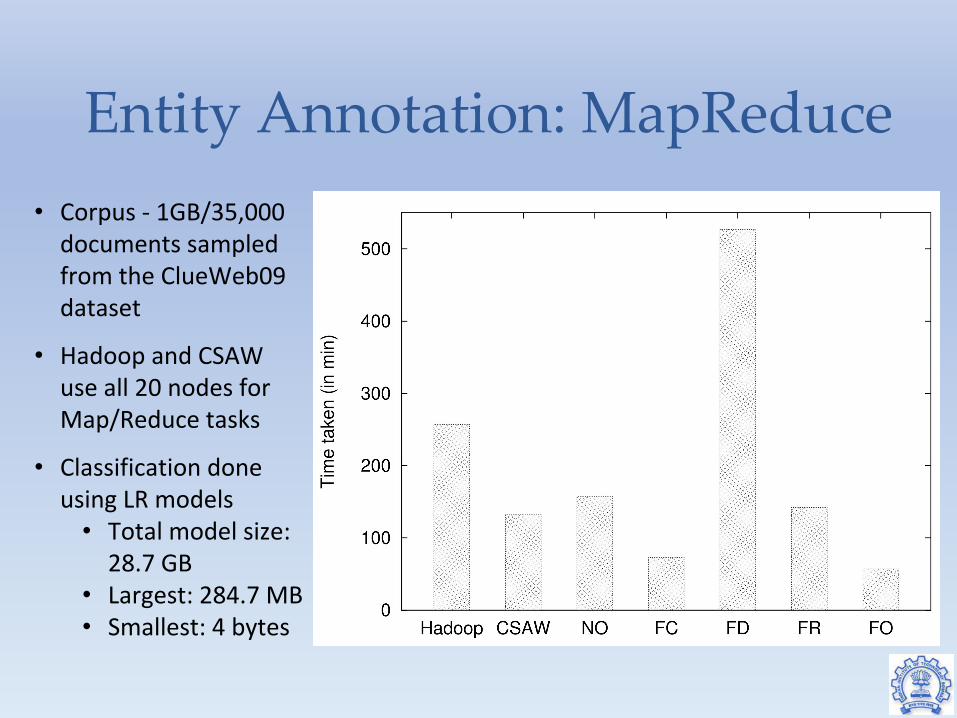
Entity Annotation: MapReduce • Corpus - 1GB/35,000
documents sampled from the ClueWeb09dataset
• Hadoop and CSAW use all 20 nodes for Map/Reduce tasks
• Classification done using LR models
• Total model size: 28.7 GB
• Largest: 284.7 MB• Smallest: 4 bytes
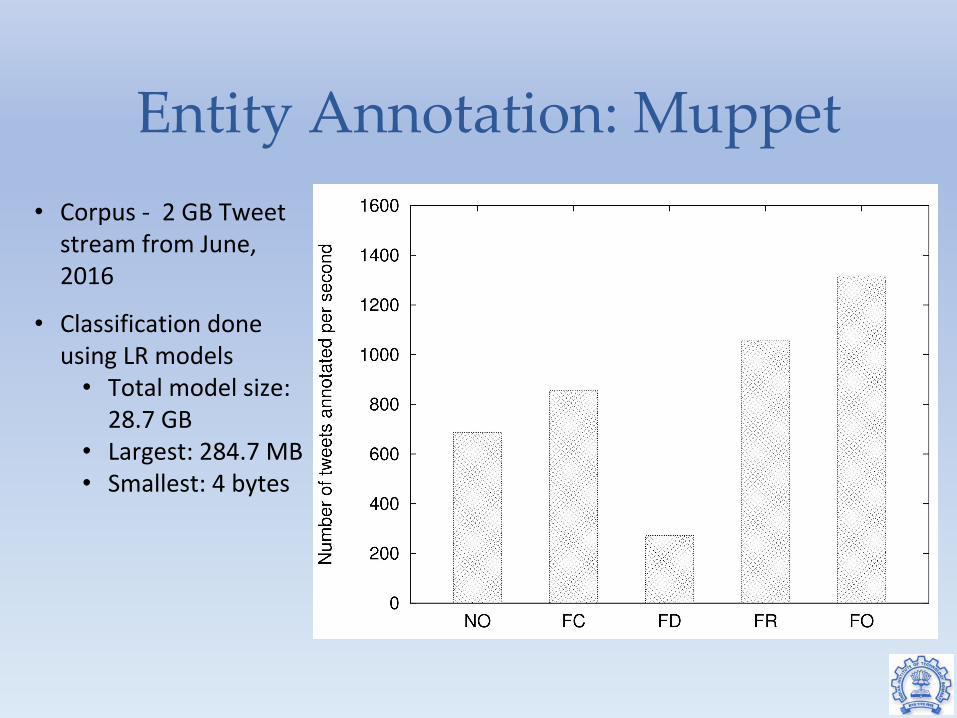
Entity Annotation: Muppet• Corpus - 2 GB Tweet
stream from June, 2016
• Classification done using LR models
• Total model size: 28.7 GB
• Largest: 284.7 MB• Smallest: 4 bytes

Conclusion• We provided simple extensions to the MapReduce and
Muppet APIs to support prefetching and batching
• Performance results show significant throughput improvement across different frameworks and workloads
• Future work• Dynamic choice of batch size and batch timeout taking latency
into account
• Handling user defined functions with side effects
• Optimizing for multiple joins in a single pipelined stage

Questions?

Backup slides

Experimental Setup• Hadoop: Basic Map Reduce in Hadoop with no skew mitigation
techniques
• CSAW: Custom partitioning based for entity annotation workload
● NO: No optimization. All function computation at compute nodes● FC: All function computations at compute node with prefetching and batching● FD: All function computations at data node with prefetching and batching● FR: Compute functions randomly at compute or data node with prefetching and batching● FO: Use optimizations to decide where to execute functions. Use prefetching and batching
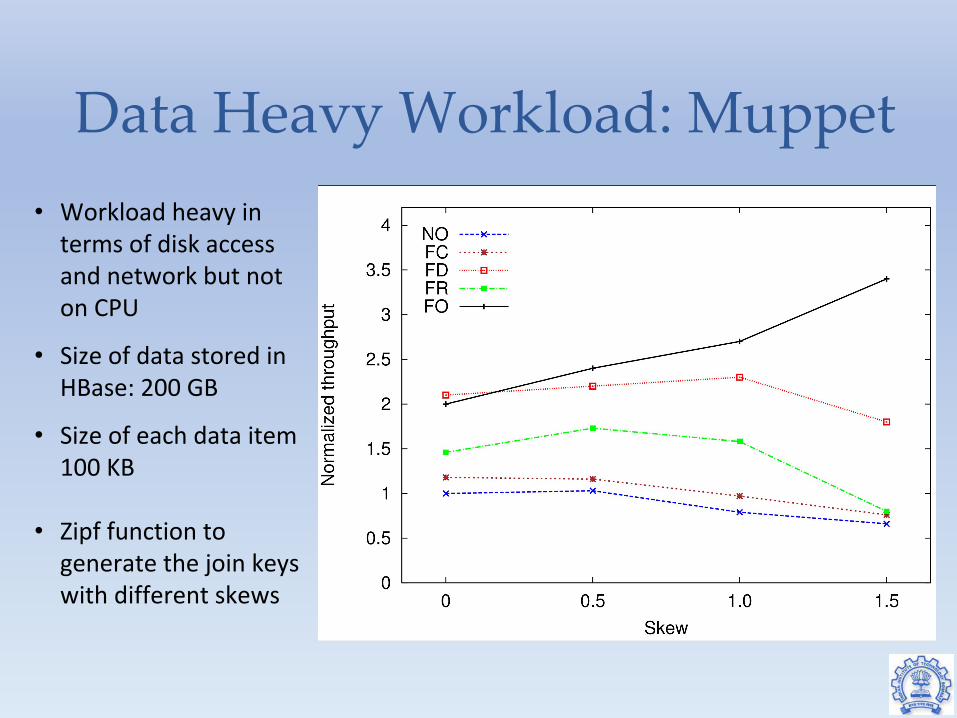
Data Heavy Workload: Muppet• Workload heavy in
terms of disk access and network but not on CPU
• Size of data stored in HBase: 200 GB
• Size of each data item 100 KB
• Zipf function to generate the join keys with different skews
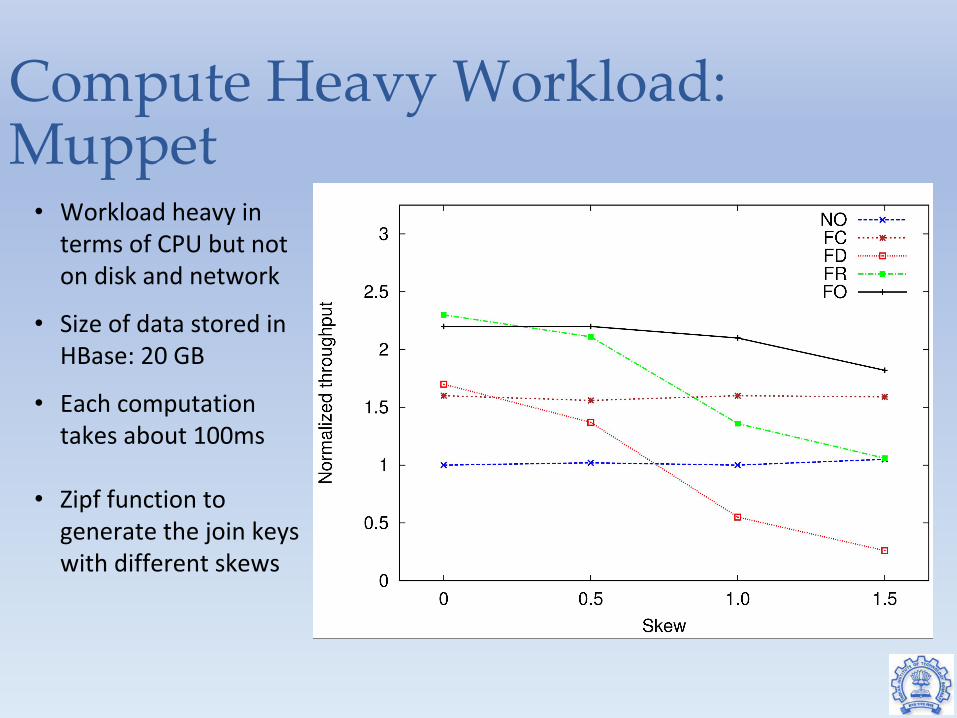
Compute Heavy Workload: Muppet
• Workload heavy in terms of CPU but not on disk and network
• Size of data stored in HBase: 20 GB
• Each computation takes about 100ms
• Zipf function to generate the join keys with different skews
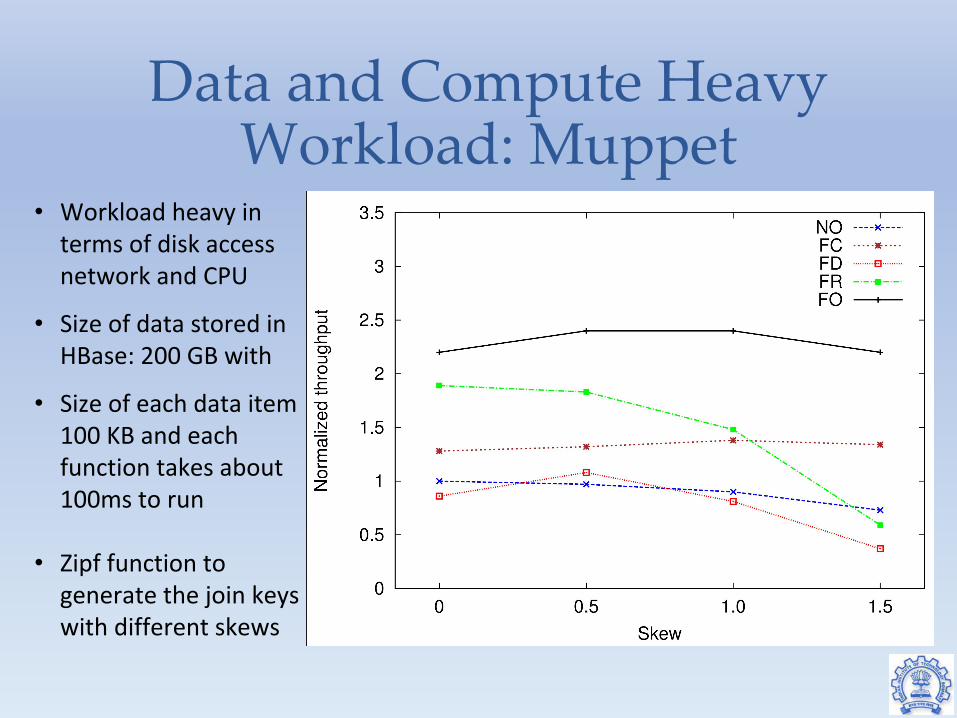
Data and Compute Heavy Workload: Muppet
• Workload heavy in terms of disk access network and CPU
• Size of data stored in HBase: 200 GB with
• Size of each data item 100 KB and each function takes about 100ms to run
• Zipf function to generate the join keys with different skews

















