15
Map Reduce: Simplified Data Processing On Large Clusters Jeffery Dean and Sanjay Ghemawat (Google Inc.) OSDI 2004 (Operating Systems Design and Implementation) Presented By - Navam Gupta
| Date post: | 26-Dec-2015 |
| Category: |
Documents |
| Upload: | allen-hill |
| View: | 227 times |
| Download: | 0 times |

Map Reduce: Simplified Data Processing On Large Clusters
Jeffery Dean and Sanjay Ghemawat (Google Inc.)
OSDI 2004 (Operating Systems Design and Implementation)
Presented By - Navam Gupta
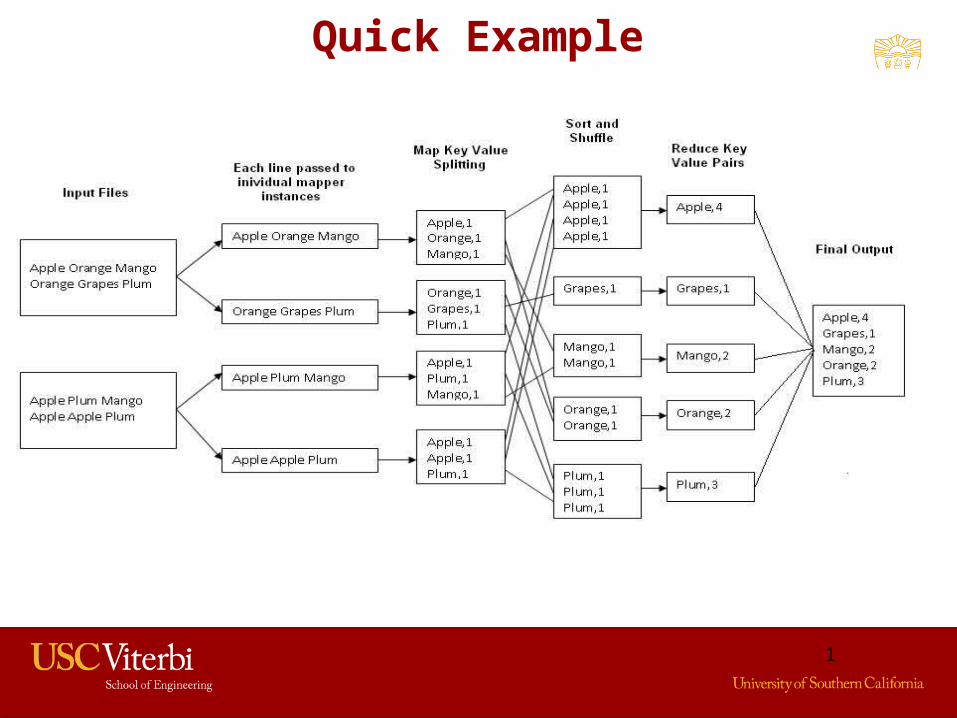
Quick Example
1
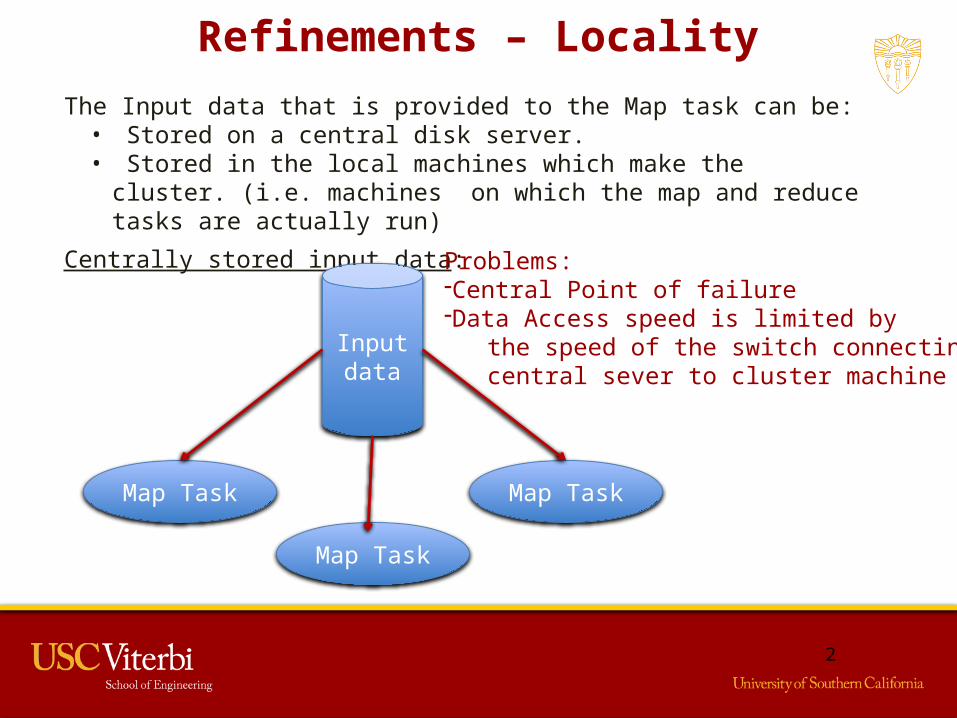
Refinements – Locality
The Input data that is provided to the Map task can be:• Stored on a central disk server.• Stored in the local machines which make the cluster. (i.e. machines
on which the map and reduce tasks are actually run)
Centrally stored input data:
Map Task
Map Task
Map Task
Inputdata
Problems:-Central Point of failure-Data Access speed is limited by the speed of the switch connecting the central sever to cluster machine
2

Refinement – LocalityStored on Local Machines – Blocks of data are stored on local machine disks.
Map Task Map TaskMap Task
Input InputInput
Machine 1 Machine 3Machine 2
Data access speed no longer limited by switch data transfer speed.
But How can we be sure that the input assigned to map task is available in its local disk? - Store multiple copies of each block on multiple machines. - Master receives a list containing the location of each block and utilizes that list to assign tasks depending on the availability of input.
3

Refinement – Locality
Map Task Map TaskMap Task
Block ABlock FBlock C
Machine 1 Machine 3Machine 2
Block ABlock BBlock F
Block FBlock BBlock C
Master
Use Input A Use Input B Use Input C
Ending Note: Solid State Drives are fast right?
4

Refinements – Partitioning Function
Number of Reduce Tasks = Number of Output Files = Provided By User= R
Generally to partition the Intermediate Keys ( the Keys generated as the output of the Map functions) into R different partitions we simply use:
Hash(Key) mod R
Say the output keys are actually URL’s and we would like all URLs of a single host/domain to end up in the same output file. Will that partitioning work ? ----- No, we need something more.
Hash(Hostnames(Key)) mod R
Hostnames is a function that returns hostname corresponding to the URL.e.g. Hostnames(www.example.com/everythingispossible) = example.com
Ending Note – Google allows overwriting of the Partitioning function.
5

Refinement – Ordering Guarantees
Within a partition (those created by the partitioning function), the intermediate key/value pairs are processed in increasing key order.
This has become a common feature now, but initially when the map-reduce model was used in Lisp/Haskell the idea was just to group similar keys and no constraint on the order of processing the keys e.g.
The problem with the latter output - what if we intend to do frequent lookup’s in the output file? In such a scenario ordered output is always better.
Ending Note - This is another reason to perform costly sorts on the intermediate keys.
Partition {<Apple,[1,1,1]>,<Banana,[1,1,1,1]>}
Output{<Apple,3>,<Banana,4>} or Output{<Banana,4>,<Apple,3>
6

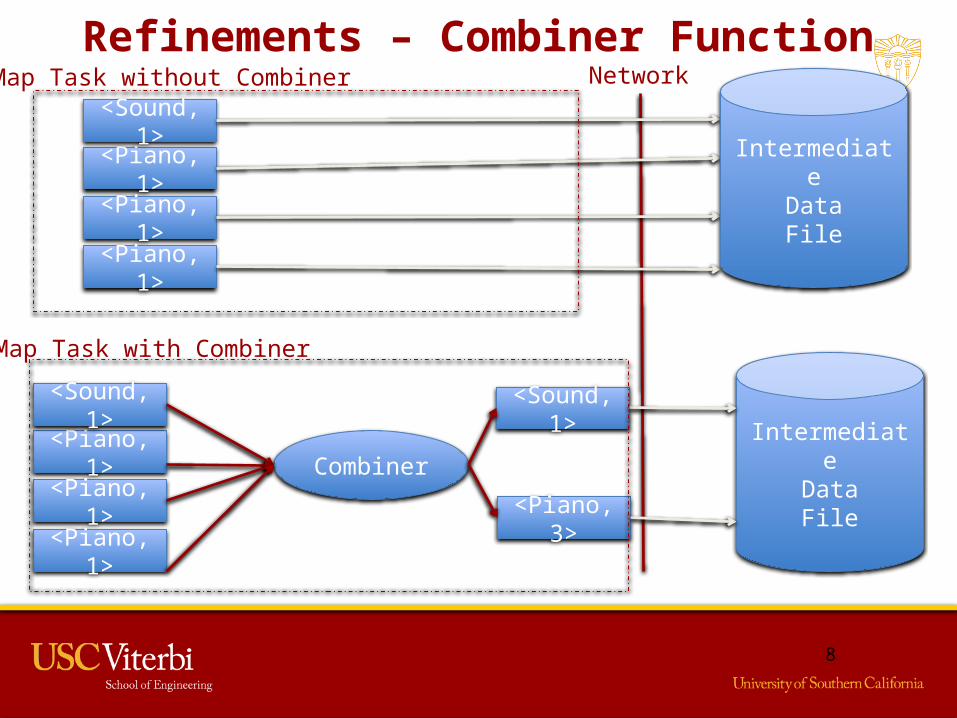
Refinements – Combiner Function
At times there is a lot of repetition in the intermediate keys produced by a Map task. For e.g. the sentence
“Piano sound is soothing. Its easy to play a piano. Pianos are awesome”The Map task will produce <Piano,1> output 3 times.
Afterwards this output is sent over the network for further processing.
But should we really waste network bandwidth sending the same data over and over again ? Why don’t we just combine it into 1 result <Piano,3> ?That is exactly what a combiner function does !
Combiner function is basically a copy of the Reduce task but :• It is executed on the same machine as the Map task, right after the
Map task completes its execution.• Unlike the Reduce task the output instead of being written into an
output file is written to the intermediate data file.
7
Refinements – Combiner Function
<Piano,1>
<Piano,1>
<Piano,1>
<Sound,1>
Network
IntermediateDataFile
<Piano,1>
<Piano,1>
<Piano,1>
<Sound,1>
Combiner
<Sound,1>
<Piano,3>
IntermediateDataFile
Map Task without Combiner
Map Task with Combiner
8

Refinements – Skipping Bad Records
Sometimes there are bugs in the code that causes Map or Reduce functions to crash on certain records e.g.
Suppose a reduce function is programmed in such a manner that it only accepts Alphabets as the Key.But if there is a record such as <L33t,4>, reduce function will always crash for this particular record and will keep on trying to re-execute it.
In general we handle crashes by fixing the bug, but sometimes its not feasible/possible like –
• Maybe caused by 3rd party tool whose source code is inaccessible.• Highly distributed environment/data makes it very hard to find the error.
In such a case we, • Install a signal handler to catch the errors• Once a particular record errors it sends “last gasp” UDP packet to
master.• If Master receives more than certain threshold for a particular record,
that record is no longer assigned to any task
9

Local Execution and Status Information
Local Execution: Map-Reduce Library is primarily meant for a highly distributed environment over thousands of machine which may or may not be in the same geographical region.
There was a need to be able to Locally Execute the program so that:• It could be tested• Debugged and • Profiled
So Map-Reduce library supports local execution on the user’s machine.
Status Information: Being able to track the progress of the execution on such a large scale distributed environment is important in order to fully utilize all the resources.
The Map-Reduce library comes with an HTTP Server, which displays pages containing information such as:• Number of Tasks completed and In Progress• Bytes of Input, Intermediate and output data.• Which worker failed and the kind of task being performed by them.
10

Status Information
11

Google Map-Reduce vs. Hadoop
In 2008, Hadoop had just begun and Doug Cutting (Yahoo employee) was one of the creators.Hence the comparison benchmarks came from Yahoo.
In 2011, it was rumored that Google drastically improved its cluster hardware causing the sudden improvement in performance.
12

If Time Permits – Map Reduce Is Everywhere!Pretty much any task that needs to process large amount of data can be Map Reduced
Content of ex.com – “wow bow how”Content of ex1.com –” bow wow”
Map input – (ex.com, “wow how”)Assume Hash of wow = “abc” , how =“def”…
Map output – {<ex.com,”abc”>,<ex.com,”def”>,…}
Reduce input – (ex.com, {“abc”,”def”,…})Reduce output – {<”abc”,ex.com-3>,<”def”,ex.com-3>}
Output of reduce1 is sent to intermediate files for grouping and sorting
Reduce input – (“abc”, {ex.com-3,ex1.com-2})Reduce output – {<ex.com-3,ex1.com-2>}
13

Everywhere!
Output of reduce2 is sent to intermediate files for grouping and sorting
Reduce input – Key is url and values represent every other url which had any shingle that was present in
the key e.g.(ex.com-3,{ex1.com-2,ex1.com-2})
ex1.com comes for bow and wow bothReduce output – {<ex.com + ex1.com,*Similarity*>}
My Conclusions• Map reduce is here to stay.• Map Reduce is the reason why Google has billions of dollars. Yes Page Rank is novel and awesome too, but without Map Reduce it would be infeasible.• Get used to it. Play with Hadoop @ hadoop.apache.org
14






![Presented by Shen Lipbg.cs.illinois.edu/.../lectures/18-MapReduce-Shen.pdfPaper List • [1] MapReduce: Simplified Data Processing on Large Clusters, J. Dean, and S. Ghemawat, OSDI’04.](https://static.documents.pub/doc/80x56/5f8d80ffff950450d4784560/presented-by-shen-lipbgcs-paper-list-a-1-mapreduce-simplified-data-processing.jpg)






![ECON480 HY International Business Varela [Fall 2015]...Ghemawat,!Harvard!Business!Review,!September!2001!! Pankaj Ghemawat is Global Professor of Management and Strategy and Director](https://static.documents.pub/doc/80x56/5eceb802ac8f391609197e5e/econ480-hy-international-business-varela-fall-2015-ghemawatharvardbusinessreviewseptember2001.jpg)

![TDDD43 HT2014: Advanced databases and data models …TDDD43/themes/themeNOSQL/...Dean, Ghemawat [OSDI'2004]: MapReduce: Simplified Data Processing on Large Clusters Karger et al. [ACM](https://static.documents.pub/doc/80x56/5f0f4a147e708231d4436c5c/tddd43-ht2014-advanced-databases-and-data-models-tddd43themesthemenosql-dean.jpg)

