Measurement Properties Validity and Reliability Mayyada Wazaify, PhD 2014 References: 1. Smith F. Survey Research: Design, Samples and Response In: Research Methods in Pharmacy Practice. 1st Ed, 2002:pp:43-59 2. Abudahab S. Clinical Research Course/ Faculty of Rehabilitation Sciences. University of Jordan. 2009
Transcript
Measurement Properties Validity and Reliability
Mayyada Wazaify, PhD2014
References:1. Smith F. Survey Research: Design, Samples and Response In: Research Methods in Pharmacy Practice.
1st Ed, 2002:pp:43-592. Abudahab S. Clinical Research Course/ Faculty of Rehabilitation Sciences. University of Jordan. 2009
Examples:- In a question to report on smoking, smokers may
consistently under-report - In a question on patients 'compliance with
medication regimen, they may tend to overestimate
•Thus the questions are of doubtful validity, even though they may be reliable in the sense that repeated questioning, would provide the same answers.
VALIDITY
What is Measurement Validity?• It is the extent to which an instrument
measures what it is intended to measure
• In survey work: the extent to which the questions collect accurate data relevant to the study objectives.
• Validation process: involves testing the instrument, in its entirety or by selecting individual questions, in the population for which it is to be used to ensure that the responses are TRUE.
• Different types of validity.
•Internal validity dictates how an experimental design is structured and encompasses all of the steps of the scientific research method
•External validity is the process of examining the results and questioning whether there are any other possible causal relationships.
Face validity (i-e prima facie)• Least rigorous method for documenting a
test’s validity • Indicates that an instrument appears to test
what is supposed to measure
• IMPORTANT ! An instrument lacking in face validity may not be acceptable to those who administer it, those who are tested by it, and those who will use the results. – UNLIKELY TO BE VALID
Face validity• Aims to uncover obvious problems: ambiguous,
misleading Q, questions that respondents would be unable or reluctant to answer or those that might not be an accurate reflection of the variable of interest.
- An instrument lacking in face validity may not be acceptable to those who administer it, those who are tested by it, and those who will use the results:- For example, respondents on a questionnaire may not
answer questions with honesty or motivation if they do not see the relevance of the questions
- Patients may not be compliant with repeated testing if they do not understand how a test relates to their difficulty
Content validity • It is concerned with the extent to which an
instrument covers all the relevant issues.
• Most useful with questionnaires
• E.g. VAS vs. MPQ
• Range of techniques- part of preliminary fieldwork leading to the development of the instrument- qualitative research, in-depth or semi-structured interviews-Delphi Method- Nominal Group technique- Literature Review
Content Validity and Face Validity • Content validation and face validation are
similar concepts, in that both are based on subjective judgments, and both indicate that test appears to be serving its intended purpose.
• The difference is that ▫Face validity is post hoc of validation; it is a
judgment made after an instrument is constructed
▫Content validity evolves out of the planning and construction of a test
FACE VALIDITY CAN BE CONSIDERED PART OF CONTENT VALIDITY
Criterion-related validity •Most practical approach •Most objective•Indicates that the outcomes of one
instrument, the target test, can be used as a substitute measure for an established gold standard or criterion measure. ▫When both tests are administered to one
group of subjects, the scores on the target test are correlated with those achieved by the criterion measure. If the correlation is high, the target test is
considered a valid predictor of the criterion score
Criterion-related validityExamples:• (GHQ28) used to screen for depression and anxiety its
criterion validity is based on the fact that a score of 5-6 on the GHQ28 correlates well with clinical diagnoses of anxiety and depression
• To validate the responses and assess reporting bias in a study of cigarette smoking based on self-reports- serum cotinine (a biochemical marker of exposure to tobacco smoke) is measured.
• Individuals’ reports of their medication use has been validated by comparing with pharmacy refill data records.
• Regression Analysis
• Correlation coefficient= validity coefficient
Criterion-related validity – Cont. • Two types
▫Concurrent validity: Establishes validity when two measures are taken at relatively the same time. This approach to validation is useful in situations when a new
or untested tool is potentially more efficient, easier to administer, more practical or safer than another more established measure, and is being proposed as an alternative instrument
▫Predictive Validity: Establishes that the outcome of the target test can be used to predict a future criterion score or outcome To assess predictive validity, a target test is given at one
session and is followed by a period of time after which the criterion score is obtained
Construct Validity •Construct validity is the hardest to
understand.
•It asks if there is a relationship between how I operationalized my concepts in this study (proxy) to the actual causal relationship I'm trying to study (construct)?
•It is concerned with whether or not a question, or group; of questions, corresponds to what is understood by a construct or concept.
Construct validity – Cont.
Example:• “Socio-economic” class
▫ Features like lifestyle, opportunities, income, wealth, outlook on life, education, housing tenure.
• “construct” (intended) vs. “proxy” (indicator, sign) variables
• Ethnicity▫ Possible classification: place of birth, nationality,
parental origins, language group, skin colour etc or a combination of these variable.
▫ Each will lead to different classifications of the same individuals
RELIABILITY
What is Reliability?
•The extent to which a measurement is consistent and free from error (how reproducible or internally consistent)
•It is fundamental to all aspects of measurement, because without it we cannot have confidence in the data we collect, nor can we draw rational conclusion from those data.
Reliability•A survey can be reliable but NOT valid
e.g.•However, it cannot be valid if it is
unreliable.
Factors that may result in poor reliability:▫ Ambiguity of question wording (e.g. double-
barrelled, double negative)▫ Inconsistent interpretation of questions by
respondents▫ Variation in the style of questioning by different
interviewers▫ Inability of respondents to provide accurate
information, leading to guesses or poor estimates▫ Questions requiring people to recall past events
•The first step in addressing reliability of data is similar to the face validity check, that is,
•To spot questions that might be expected to be inaccurately answered (pilot work)
•Variation between interviewers
•There are two ways that reliability is usually estimated: Test/Re-test and Internal consistency
Reliability
•The primary difference between
test/retest and internal consistency
estimates of reliability is that test/retest
involves two administrations of the
measurement instrument, whereas the
internal consistency method involves only
one administration of that instrument.
Internal Consistency Example• Consider this scenario: respondents are asked to
rate the statements in an attitude survey about computer anxiety.
• One statement is: "I feel very negative about computers in general." Another statement is: "I enjoy using computers." People who strongly agree with the first statement should be strongly disagree with the second statement, and vice versa.
• If the rating of both statements is high or low among several respondents, the responses are said to be inconsistent and patternless.
Internal Consistency
1. Split-half Method• Data divided into 2 halves-analyzed
independently results compared
2. Cronbach’s alpha (0-1)• Reflects correlations between
questionnaire items which are intended to be part of the same measure
• A figure ≥ 0.7 acceptable
Types of Reliability • Test-retest reliability (Temporal Stability)
▫Establish that an instrument is capable of measuring a variable with consistency In test-retest study, one sample of individuals is subjected to
the identical test on two separate occasions, keeping all testing conditions as constant as possible.
▫Test-retest intervals The time interval should be considered carefully. Should be enough apart to avoid fatigue, learning, or memory
effects BUT close enough to avoid genuine changes in the measured variable
▫Carryover and Testing effects Carryover effect can occur with repeated measurements,
changing performance on subsequent trials. Testing effect: occurs when the test itself is responsible for the
observed changes in a measured variable
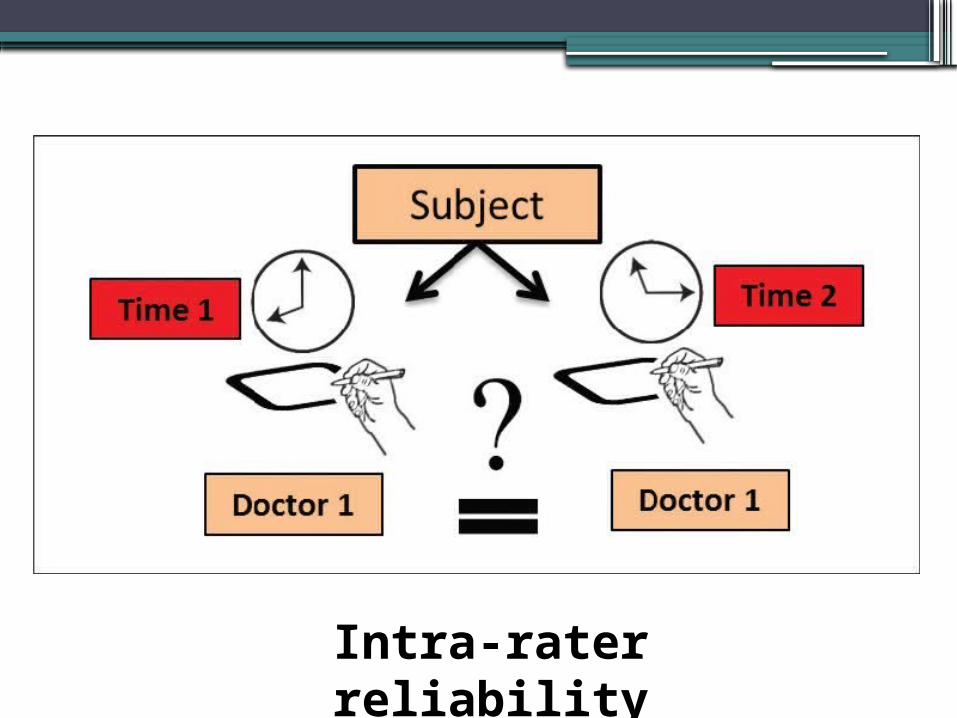
Types of Reliability – Cont. •Intrarater Reliability
▫Stability of data recorded by one individual (or device) across two or more trials
▫Rater bias Raters can be biased by their memory of the
first score, can be controlled by: blinding the score from the rater which almost
impossible in clinical research Developing grading criteria that are as
objective as possible, to train the testers in the use of the instrument, and to document reliability across raters
Intra-rater reliability
Types of Reliability – Cont. •Interrater Reliability
▫Concerns variation between two or more raters who measure the same group of subjects. Intrarater reliability should be established for
each individual rater before comparing between raters with each other
Best assessed when all raters are able to measure a response during a single trial, where they can observe a subject simultaneously and independently, which is not usually possible in clinical research.
In clinical research, researchers often decide to use one rater to void the necessity of establishing interrater reliability
Interrater reliability
HOMEWORK-1 (5 marks)
•Write down a different example of each of the following:
•Content validity•Construct validity•Criterion validity•Internal consistency•Itrarater and Interrarter reliability