55
Statistical Machine Translation Gary Geunbae Lee Intelligent Software Laboratory, Pohang University of Science & Technology
| Date post: | 24-Dec-2015 |
| Category: |
Documents |
| Upload: | bertram-dennis |
| View: | 219 times |
| Download: | 0 times |

Statistical Machine Translation
Gary Geunbae Lee
Intelligent Software Laboratory,
Pohang University of Science & Technology

Contents
• Part1: What Samsung requires to survey
– Rule-base and Statistical approach
– Alignment Model
– Decoding Algorithms
– Open Sources
– Evaluation Methods
– Using Syntax Info. in SMT
• PartII: State-of-the-art technology
• PartIII: SMT/SLT in Isoftlab

Recent Technology• Variants of phrase-based system
– Factored Translation Model• Variants of other system
– Variants of n-gram based translation– Variants of syntax based translation
• Word alignment for SMT• Parameter optimization • Reordering• Others
– Evaluation– Language Model– Domain adaptation– …
Technologies of red text will be introduced in this presentation
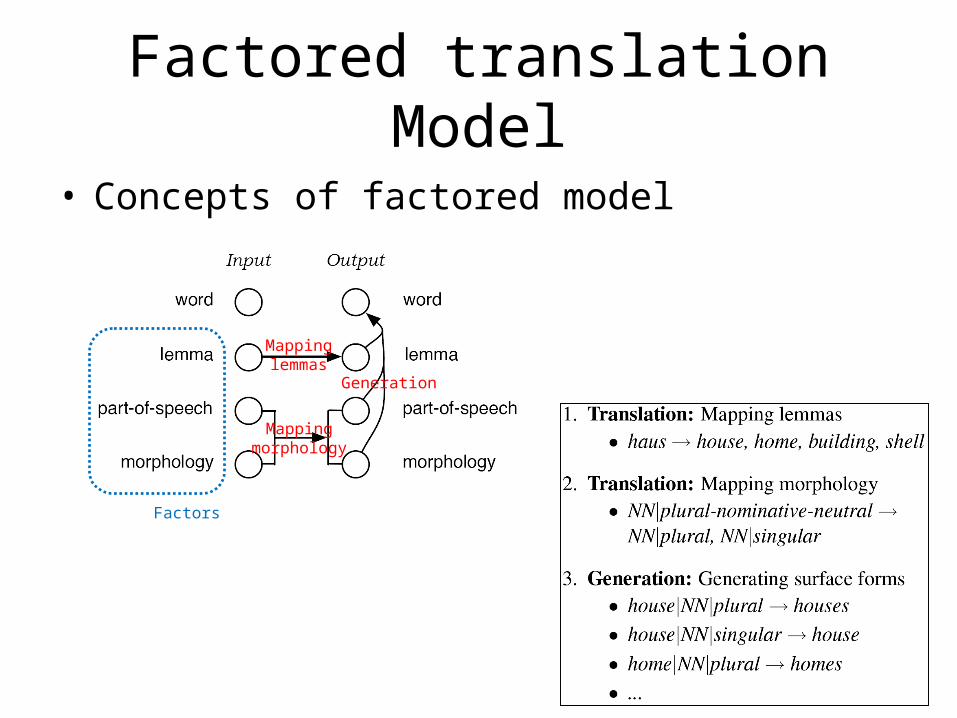
Factored translation Model
• Concepts of factored model
Mapping lemmas
Mapping morphology
Generation
Factors

Factored translation Model
• Performance (higher order n-gram)
Europarl : 751,088 sent.Factor 7-gram LM
Europarl : 40,000 sent.Factor 7-gram LM
WSJ : 20,000 Sent.Factor 7-gram LM

Factored translation Model
• Performance ( analysis and generation )
Phrase-based Model
Ignore surface form
Use surface form for statistically rich words.Use analysis and generation model for statistically poor words.
News Commentary 52,185 sent.

N-gram based machine translation
• Concept– “The n-gram based SMT system uses a translation model based
on bilingual n-grams”– Bi-lingual N-gram
• Bi-lingual phrase pair• Consistent with word alignment• Minimal unit (monotone translation)
– SMR : statistical machine reordering• “translates from original source language (S) to a
reordered source language (S’), given target language(T)”

N-gram based machine translation
• Bilingual pair example
Original training source corpus
Reordered training source corpus

N-gram based machine translation
• Performance
Europarl corpus: wmt07 shared taskSettings:4-gram translation model5-gram target LM5-gram target class LM
Baseline is Moses decoder with no factors. That is, standard phrase-based model

Word alignment for SMT
• Word packing– Concept:
• To assume and treat “several consecutive words as one word”– Condition:
• There are some evidences that “the words correspond to a single word in opposite side”
• Evidence: Co-occurrence– Example:
• Where is the department store?
• 그 백화점은 어디에 있습니까 ?
packing

• Alignment procedure
Word alignment for SMT
AlignerExtract 1-n alignment
Prune-outTarget Side Substitution
Source textTarget text
AlignmentResult
Candidates to pack
Word lists to pack
Modified Target text
Manual Dictionary

Word alignment for SMT
• Performance
BTEC Corpus
Phrase-based system trained with Model-4
n: # of iterations

Parameter Optimization
• Parameters– Most state-of-the-art SMT systems use log-linear models– Parameters are the weights of the model that used in the log-
linear model
• Minimum error rate training (MERT)– maximizing BLEU score by tuning parameters iteratively– Proposed by F. J. Och (2003)– Most research include this process

Parameter Optimization
• MERT Process
Decoder Evaluator
Parameter Update
DevSet Ref.
New parameters
Evaluation Result
Translation Result
DevSet Src.
Fact: Evaluation result affect directly parameter tuningAssumption1 :More reliable evaluation can leads better estimationAssumption2 : More ref. makes the evaluation accurate.Goal : Automatic generation of additional Refs.

Parameter Optimization
• Paraphrasing– English to English problem with a pivot language
– Two alignments• English to French
• French to English
– Examplee1f2e2e1f1e3e1f2e4e2f2e1e2f2e4

Parameter Optimization
• Paraphrasing results– Pivot language : French
Parameter Optimization
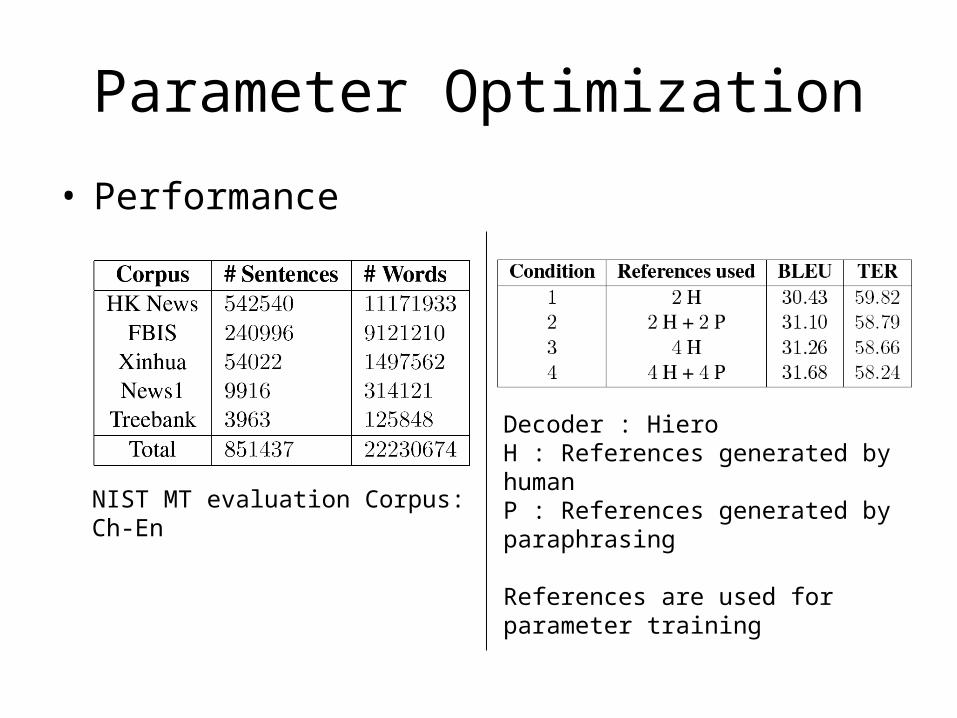
• Performance
NIST MT evaluation Corpus: Ch-En
Decoder : HieroH : References generated by humanP : References generated by paraphrasing
References are used for parameter training

Latest Shared-task: wmt07
• Summary of participant
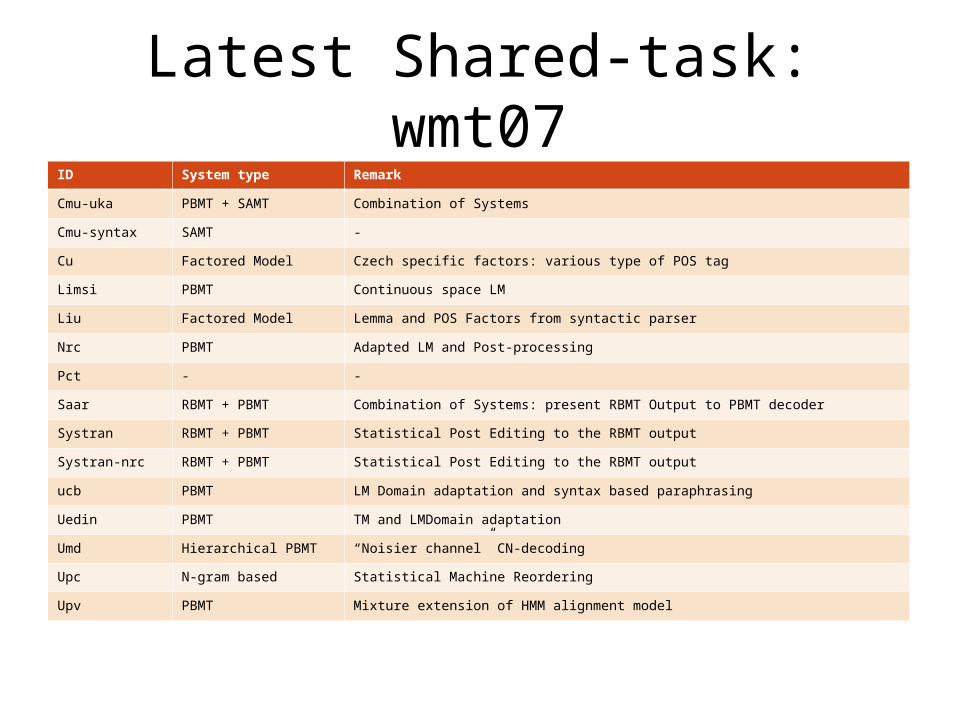
Latest Shared-task: wmt07ID System type Remark
Cmu-uka PBMT + SAMT Combination of Systems
Cmu-syntax SAMT -
Cu Factored Model Czech specific factors: various type of POS tag
Limsi PBMT Continuous space LM
Liu Factored Model Lemma and POS Factors from syntactic parser
Nrc PBMT Adapted LM and Post-processing
Pct - -
Saar RBMT + PBMT Combination of Systems: present RBMT Output to PBMT decoder
Systran RBMT + PBMT Statistical Post Editing to the RBMT output
Systran-nrc RBMT + PBMT Statistical Post Editing to the RBMT output
ucb PBMT LM Domain adaptation and syntax based paraphrasing
Uedin PBMT TM and LMDomain adaptation
Umd Hierarchical PBMT “Noisier channel” CN-decoding
Upc N-gram based Statistical Machine Reordering
Upv PBMT Mixture extension of HMM alignment model

Latest Shared-task: wmt07
• Human evaluation– Adequacy, fluency, rank and constituent
Rate of top-ranked count
PBMT+RBMTPBMT
NBMTPBMT
HPBMTPBMT
PBMT+RBMT-
PBMTFactored

Latest Shared-task: wmt07
• Automatic evaluation– 11 metrics including METEOR, BLEU, TER, ...
Rate of top-ranked count
PBMTNBMTPBMT
HPBMTFactored
SAMTPBMT+SAM
TPBMTPBMT
PBMT+RBMTPBMT+RBMTPBMT+RBMT

Contents
• Part1: What Samsung requires to survey
– Rule-base and Statistical approach
– Alignment Model
– Decoding Algorithms
– Open Sources
– Evaluation Methods
– Using Syntax Info. in SMT
• PartII: State-of-the-art technology
• PartIII: SMT/SLT in Isoftlab

SMT in ISoft. Lab.
• For Korean-English
• Pre-processing techniques
• Compound Sentence Splitting
• Class Word Substitution & Sub-translation

Differences between Korean and English
English Korean
Spacing Unit Word Eojeol
Word Order SVO SOV
Plural Strictly distinguished
Not strictly distinguished
Honorific term Not so much Complex
Case marker Not exist Exist
Article A, An, The Not exist
Others… Tendency to omit subject in spoken language

Spacing Unit Difference
• Morpheme– Unit of meaning
– Best spacing unit for SMT system
• Pseudo-morpheme– morpheme, but some morphemes are not separated
– well correspond to acoustic signal
– spacing unit for ASR
• Eojeol– Human friendly spacing unit

Spacing Unit Difference
• English– Words well corresponds morphemes
– No need to change spacing unit
• Korean– Words(eojeol) is different from morpheme
– Need to change spacing unit
• Spacing unit can be changed automatically by just applying POS tagger.
Unit Good for Example
Morpheme SMT 걷 ㄹ 어서 거기 까지 얼마나 걸리 ㅂ니까Pseudo-
morphemeASR 걸 어서 거기 까지 얼마나 걸립니까
eojeol Human 걸어서 거기까지 얼마나 걸립니까

Word Order Difference
• English is SVO language while Korean is SOV language.
• Long distance distortions are observed frequently.
저 는 술 마시 는 것 을 그다지 좋 아 하 지 않 습니다
I don't enjoy drinking very much

Difference in expression
• plural and singular– English: plural form and singular form are strictly
distinguished.– Korean: plural nouns can be written in singular form– Example:
• He have 3 children. /그는 아이가 세 명 있다 .• strictly … child = 아이 , children = 아이들
• honorific terms– English: not so much distinction.– Korean: various level of distinction.– Example: go / 간다 , 가네 , 가오 , 갑니다 , 가 , 가요

Un-translatable words
• Case Markers– English doesn’t have case markers.– No English words correspond to “ 은 , 는 , 이 , 가 , 을 , 를 ,
…”
• Articles– Korean doesn’t have articles– Usually they are not translated into specific words.
• Subjects– In a Korean sentence, subject can be omitted. – In Spoken language this phenomena appears more frequently.– The subject of English sentence can not be aligned to a Korean
word.

The Techniques
• Adding Part Of Speech information– Spacing Unit problem
• Reordering word sequence– Word order problem
• Deleting useless words– Un-translatable words– Differences in expression
• Language modeling by parts• Appending dictionary

Adding POS information
• Motivation– For Korean language, Spacing Unit of ASR Result (or human written
text) should be changed into morpheme unit.
– Korean Morpheme analysis is usually accomplished by full POS tagging
– Some homographs can be distinguished by their POS tag
• How did we do ?– just changed the training and test corpus.
Original corpus 이 시계 가격 은 얼마 이 ㅂ니까
POStagged corpus 이 /MM 시계 /NNG 가격 /NNG 은 /JX 얼마 /NNG 이 /VCP ㅂ니까 /EF

Re-ordering word sequence
• Motivation– Differences in word order– Previous research: M. Collins et. al. “Clause
restructuring for Statistical Machine Translation”
• How did we do?– Parse training corpus and analyze the result– Manually generated reordering rule– Applied the rules to train and test corpus

Deleting Useless Words
• Motivation– Un-translatable words make word alignment worse. – Various endings caused by Honorific expression increase
vocabulary size. But they can not play an important role in translation.
– these words are “useless” in translation.
• How did we do?– Applied POS tagger– Using the POS tagged, delete the words with specific tags
from the train and test corpus

Language Modeling by Parts
• Motivation– Assume that translation does not change the category of a
given sentence.– Sentence classification is possible.– Smaller language model has less ambiguity
• How did we do?– Checking the end of Korean sentences, classify train and
test corpus into 2 classes: interrogative and others.– Build language model for each class of train corpus– while decoding, classify input sentence and select
appropriate language model

Appending dictionary
• Motivation– GIZA++ supports dictionary, but only word to word
dictionary– Phrase dictionary would more be helpful– we expected one more count to the exact alignment while
GIZA++ training
• How did we do?– Dictionary has word pairs and phrase pairs in general
domain– Just append the dictionary to the end of corpus

Experiment
• Corpus Statistics– Train : 41,566 sentences
– Test : 4,619 sentences
– Dictionary : about 160K entries
Korean English
BaselineTraining 190,418 279,918
Test 21,111 31,042
POS tagged
Training 360,102 296,908
Test 39,955 32,936
Deleting Useless
Training 290,991 296,908
Test 32,346 32,936

Experiment
• Experimental Result

Compound sentence splitting
• A problem of Korean – English translation– Longer sentence leads longer reordering– Simple distortion model in a standard phrase-based
model prefers monotone decoding– Long sentence reordering error Word salads
• Solution– Make long sentences short– Split long sentence into short sub-sentences

Concept of Transformation
• Rewriting Rule– T1 T2
• Triggering Environment– Sequence of words, tags …
– A precondition for the rewriting rule
• ExampleRewriting Rule
Triggering EnvironmentSource Tag Target Tag
NN VB Previous tag is TO
VBP VB One of the previous three tags is MD
JJR RBR Next tag is JJ
VBP VB One of the previous two words is n’t
Table: Christopher D. Manning and Hinrich Schutze. Foundations of Statistical Natural Language Processing. Page 363

Transformation for Sentence Splitting
• Triggering Environment– Morpheme sequence
– POS tag sequence
• Rewriting rule– connecting morpheme sequence (Tagged form)
– Ending morpheme sequence (Tagged form)
• Splitting position
• Junction pattern

Extracting Rewrite Rule
• Minimum Edit-distance 로 정렬해서 서로 다른 부분을 Rewriting Rule 로 뽑는다 .– 부었는데 부었어요 . ( rewriting rule )
Null 삔 발목이 부었는데 어떻게 하나요 ?
Null 0 1 2 3 4 5
삔 1 0 1 2 3 4
발목이 2 1 0 1 2 3
부었어요 .
3 2 1 1 2 3
어떻게 4 3 2 2 1 2
하나요 . 5 4 3 3 2 1

Expanding a triggering environments
• Expanding algorithm
• Mis-splitting– Splitting a sentence that is not split by human– Splitting result is not same to human’s
• The algorithm gives an error-free transformation (on example)
T := a transformation to expandfor each example E
while T mis-splits EExapnd T
endend

Initial Transformation
AMorphemes
POS tags
Sub-sentence Sub-
sentence
Window 1
Window 2
Re-writing Rule : Change A to ending morpheme followed by a Junction.
Boundary

Expanded Transformation
AMorphemes
POS tags
Sub-sentence Sub-
sentence
Window 1
Window 2
Re-writing Rule : Change A to ending morpheme followed by a Junction.
Boundary
Forward Backward

Learning Algorithm
• Original TBL (Used in Brill Tagger )– Minimize Error rate
– Training example is modified by training
• TBL for Sentence Splitting– Maximize BLEU score
– Training example is not modified by training

Applying Transformations
1. Find Available Transformations– Check Triggering environment
2. Apply rewriting rule– Connecting morpheme ending morpheme
3. Split Sentence
4. Decode two sentences
5. Connect the sentences with Junction

Result
• Experimental result
Test No.
Lex Pos
#of transformati
ons
#of chang
es
# of superi
or
# of inferio
r
# of draws
#of total
1 None None 16 23 5 2 16
1577
2 NoneForwar
d153 135 36 14 86
3 None Free 192 109 33 14 62
4Forwar
dNone 274 8 1 2 5
5Forwar
dForwar
d191 108 35 14 59
6Forwar
dFree 190 104 33 11 60
7 Free None 244 8 1 2 5
8 FreeForwar
d151 115 25 16 74
9 Free Free 190 101 28 12 61

Class word substitution for SMT
NE Tagged Corpus : Original Corpus
[ 한국 /Loc] 에서 왔습니다 .
I’m from [Korea/Loc].
NE Dictionary Name, Location ..
한국 Korea Loc
NE Substituted Corpus Learn phrase
[Loc] 에서 왔습니다 .
I’m from [Loc].
Why we use class words?We can get richer statistics by using class words.

Class word substitution for SMT
• Decoding
Input SentenceNE Substituted
Sentence
Translation Option
Decoding
NE re-Substitution Output Sentence
NE DictionaryAutomata
The substituted class words compete against original words while decoding.
We hope that the original words defeat class words if the substitution was erroneous
The Decoder should be trained with corpus containing class word substituted sentences

Spoken language translation
• Major components– Automatic Speech Recognition (ASR)
– Machine Translation (MT)
– Text-to-Speech (TTS)
ASRASR MTMT TTSTTSSourceSpeech
SourceSentence
TargetSentence
TargetSpeech
버스 정류장이어디에 있나요 ?
Where isthe bus stop?

Confusion network
Lattice
Confusion Network

CN-based decoder
• Decoding– Log-linear model
– Feature functions• Language model• Fertility models• Distortion models• Lexicon model• Likelihood of the path within CN• True length of the path

CN-based decoder
• Compare to N-best methods– N-best Decoder
• Does not get advantage from overlaps among N-best
– CN Decoder• Exploits overlaps among hypotheses

Experiments
• Results (SLT)
BLUE Eojeol MorphemePseudo-
morpheme
Text 0.1604 0.2974 0.2870
1-best 0.1219 0.1533 0.1753
CN (1-best) 0.1221 0.1547 0.1756
N-best 0.1391 0.1646 0.1864
CN (Full) 0.1530 0.1825 0.1827

Demo Video
• The demo video of POSSMT/KE
• The demo video of POSSMT/KJ
• The demo video of POSSLT

















